


Cách xây dựng Dashboard giám sát VPS Linux với Prometheus và Grafana
Sau khi đã cài đặt các công cụ cần thiết, bước tiếp theo và thú vị nhất chính là tự tay tạo ra một Dashboard giám sát VPS chuyên nghiệp. Các bài viết trước đã giúp bạn có một dashboard import sẵn, nhưng nó giống như một “hộp đen” khó tùy chỉnh.
Bài viết này sẽ hướng dẫn bạn toàn bộ quy trình từ tư duy thiết kế, viết truy vấn PromQL cho đến các kỹ thuật nâng cao. Mục tiêu là để bạn không chỉ có một sản phẩm, mà còn sở hữu kỹ năng để làm chủ hoàn toàn hệ thống giám sát của mình.
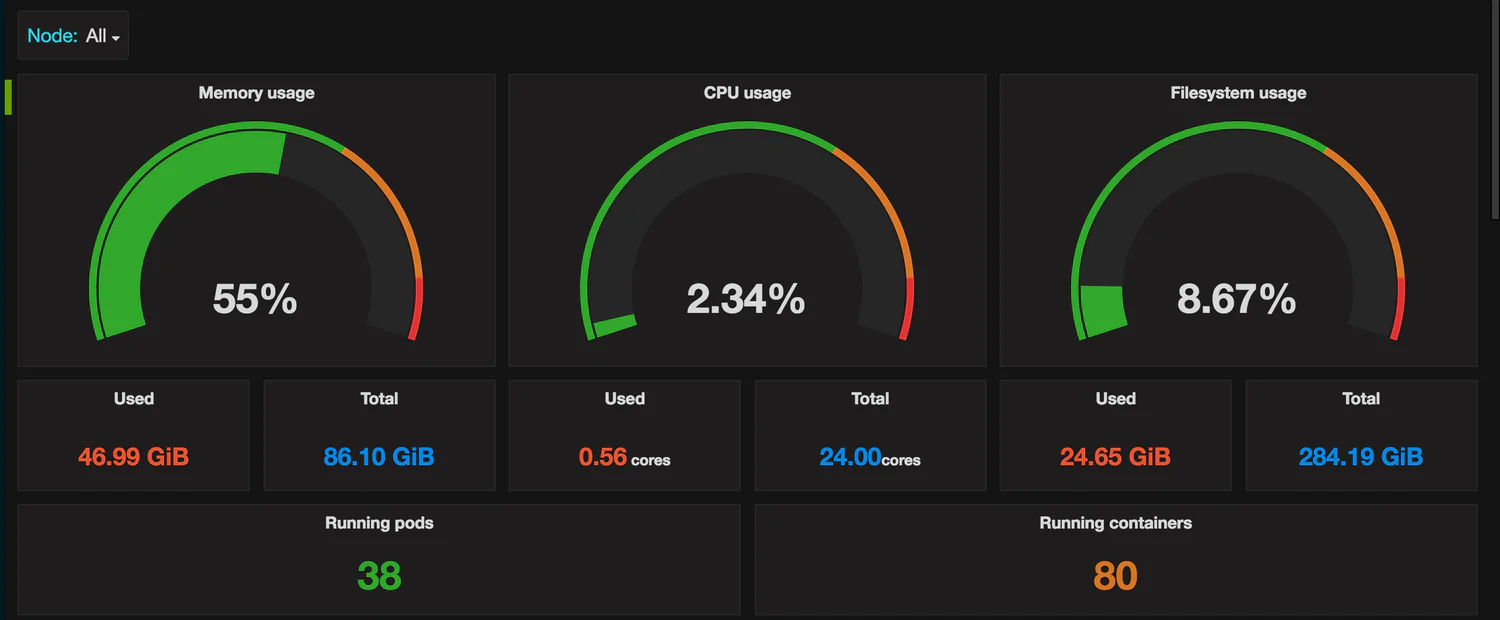
Dashboard với các đồng hồ đo CPU, RAM
Yêu cầu: Bài viết này giả định bạn đã hoàn thành việc cài đặt theo Cài đặt Prometheus và Node Exporter và Bài 3: Hướng dẫn thiết lập Grafana Dashboard đầu tiên.
Tóm tắt nhanh: Bạn sẽ học được gì trong bài viết này?
- Tư duy thiết kế một dashboard giám sát hiệu quả: Xác định các chỉ số quan trọng (CPU, RAM, Network) và chọn loại biểu đồ phù hợp cho từng loại dữ liệu.
- Viết các truy vấn PromQL thực tế: Cung cấp các đoạn mã cụ thể, đã được kiểm chứng để lấy dữ liệu CPU, RAM, Network từ Node Exporter.
- Làm chủ các tính năng nâng cao của Grafana: Hướng dẫn sử dụng Biến (Variables) để giám sát nhiều VPS trên một giao diện duy nhất và Hàng (Rows) để tổ chức dashboard một cách khoa học.
- Xây dựng một dashboard hoàn chỉnh từ con số không: Thay vì chỉ dùng sản phẩm có sẵn, bạn sẽ được hướng dẫn từng bước để tự tay tạo ra một dashboard của riêng mình, hiểu rõ cách nó hoạt động.
Tư duy thiết kế một Dashboard giám sát VPS hiệu quả
Trước khi bắt tay vào thực hành, việc định hình một tư duy thiết kế rõ ràng là cực kỳ quan trọng. Một dashboard hiệu quả không phải là nơi chứa mọi chỉ số, mà là nơi trình bày thông tin cốt lõi một cách trực quan và dễ hiểu nhất.
- Xem thêm: Tầm quan trọng của giám sát VPS & các công cụ phổ biến – VPS Chính hãng, Các phương pháp giám sát VPS & Best Practices – VPS Chính hãng
Xác định các chỉ số (Metrics) quan trọng nhất
Với một VPS Linux, chúng ta cần tập trung vào bốn trụ cột tài nguyên chính. Việc hiểu rõ vai trò của chúng sẽ giúp bạn biết mình cần theo dõi những gì và tại sao.
CPU (Central Processing Unit)
CPU là bộ não xử lý mọi tác vụ của server. Việc theo dõi CPU giúp bạn biết server có đang bị quá tải hay không. Hai chỉ số chính cần quan tâm là CPU Usage (Phần trăm sử dụng) và CPU Load (Tải trung bình hệ thống).
Memory (RAM)
RAM là bộ nhớ truy cập ngẫu nhiên, nơi lưu trữ dữ liệu cho các ứng dụng đang chạy. Giám sát RAM giúp bạn tránh được tình trạng hết bộ nhớ (Out of Memory), một trong những nguyên nhân phổ biến gây treo hoặc làm chậm hệ thống nghiêm trọng.
Disk (Ổ đĩa)
Ổ đĩa ảnh hưởng đến khả năng lưu trữ và tốc độ truy xuất dữ liệu. Chúng ta cần theo dõi Disk Space (Dung lượng trống) để tránh bị đầy ổ, gây lỗi cho ứng dụng. Bên cạnh đó, Disk I/O (Tốc độ đọc/ghi) cũng rất quan trọng vì nó ảnh hưởng trực tiếp đến hiệu năng database và website.
Network (Mạng)
Mạng là cửa ngõ giao tiếp của VPS với thế giới bên ngoài. Việc theo dõi lưu lượng mạng ra/vào (Network Traffic) giúp bạn kiểm soát việc sử dụng băng thông, phân tích hành vi người dùng và phát hiện sớm các hoạt động bất thường như tấn công DDoS.
Lựa chọn loại biểu đồ (Panel) phù hợp
Grafana cung cấp rất nhiều loại biểu đồ, nhưng việc chọn đúng loại sẽ giúp dữ liệu “biết nói”. Mỗi loại biểu đồ được sinh ra để trả lời một câu hỏi cụ thể.
Biểu đồ Gauge
Loại biểu đồ này hoàn hảo để trả lời câu hỏi: “Ngay bây giờ thì sao?”. Nó hiển thị một giá trị tức thời, thường là dưới dạng phần trăm. Đây là lựa chọn lý tưởng để xem nhanh trạng thái hiện tại của một tài nguyên.
- Ví dụ: % CPU đang sử dụng, % RAM đã dùng.
Biểu đồ Time series
Đây là loại biểu đồ phổ biến và mạnh mẽ nhất, dùng để trả lời câu hỏi: “Xu hướng thay đổi theo thời gian như thế nào?”. Nó vẽ nên một câu chuyện về hiệu suất hệ thống, giúp bạn phát hiện các xu hướng, các đỉnh đột biến hoặc các thay đổi bất thường.
- Ví dụ: Lưu lượng mạng trong 24 giờ qua, tải hệ thống.
Biểu đồ Stat
Khi bạn chỉ cần hiển thị một con số duy nhất thật nổi bật, Stat là lựa chọn hoàn hảo. Nó giúp tập trung vào một thông tin quan trọng mà không cần biểu đồ phức tạp.
- Ví dụ: Thời gian hoạt động (Uptime) của server, tổng dung lượng ổ đĩa.
Thực hành: Xây dựng Dashboard từ con số không
Bây giờ, chúng ta sẽ áp dụng những tư duy trên vào việc xây dựng từng thành phần cho dashboard của mình.
Các bước chuẩn bị trong Grafana
Đầu tiên, hãy tạo một không gian làm việc mới. Từ menu bên trái của Grafana, chọn Dashboards. Sau đó, nhấp vào nút New và chọn New Dashboard. Grafana sẽ mở ra một dashboard trống, sẵn sàng để bạn sáng tạo. Hãy bắt đầu bằng cách nhấp vào + Add visualization.
Xây dựng Panel giám sát CPU
Panel 1: CPU Usage (%) – Biểu đồ Gauge
Dashboard với các đồng hồ đo CPU, RAM
- Mục tiêu: Hiển thị phần trăm CPU đang được sử dụng tại thời điểm hiện tại.
- Loại biểu đồ: Ở danh sách bên phải, chọn Gauge.
- Truy vấn PromQL:
Trong tab “Query”, hãy nhập truy vấn sau. Truy vấn này tính toán phần trăm CPU không ở trạng thái nhàn rỗi, tức là phần trăm đang được sử dụng.100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) - Giải thích truy vấn:
node_cpu_seconds_total{mode="idle"}: Lấy tổng số giây mà CPU ở trạng thái nhàn rỗi.rate(...[5m]): Tính toán tốc độ tăng trung bình của số giây nhàn rỗi trong 5 phút gần nhất.avg by (instance) (...) * 100: Lấy giá trị trung bình theo từng instance (VPS) và nhân với 100 để ra tỷ lệ phần trăm.100 - ...: Lấy 100 trừ đi phần trăm nhàn rỗi để ra phần trăm CPU đang sử dụng.
- Chú thích về khoảng thời gian
[5m]:
Một câu hỏi thường gặp là tại sao lại chọn[5m]? Khoảng thời gian này (range vector) nên lớn hơn ít nhất 2 lần, và lý tưởng là 4 lần, so với tần suất lấy mẫu (scrape_interval) trong Prometheus. Vớiscrape_intervalmặc định là 15 giây,[5m]là một lựa chọn an toàn đểrate()tính toán tốc độ một cách chính xác và mượt mà, tránh các đột biến giả. - Cấu hình Panel:
- Ở mục Panel options bên phải, đặt Title là
CPU Usage. - Tìm mục Unit và chọn Percent (0-100).
- Trong mục Thresholds, bạn có thể đặt ngưỡng để màu sắc thay đổi, ví dụ: Base (xanh), 80 (vàng), 90 (đỏ).
- Nhấn Apply ở góc trên bên phải để lưu panel.
- Ở mục Panel options bên phải, đặt Title là
Panel 2: CPU Load Average – Biểu đồ Time series
- Mục tiêu: Theo dõi tải trung bình của hệ thống ở các khoảng thời gian 1, 5, và 15 phút để có cái nhìn toàn cảnh về xu hướng tải (ngắn hạn, trung hạn và dài hạn).
- Loại biểu đồ: Chọn Time series.
- Truy vấn PromQL:
Chúng ta sẽ thêm cả ba chỉ số vào cùng một biểu đồ để có cái nhìn toàn cảnh nhất.- Query A:
node_load1 - Nhấn + Add query. Query B:
node_load5 - Nhấn + Add query. Query C:
node_load15
- Query A:
- Cấu hình Panel:
- Đặt Title là
CPU Load Average. - Ở mục Legend, bạn có thể tùy chỉnh cho từng truy vấn để dễ phân biệt, ví dụ:
{{instance}} - 1m load,{{instance}} - 5m load,{{instance}} - 15m load. - Nhấn Apply.
- Đặt Title là
Xây dựng Panel giám sát RAM
Panel 3: RAM Usage (%) – Biểu đồ Gauge
- Mục tiêu: Hiển thị phần trăm bộ nhớ RAM đã được sử dụng.
- Loại biểu đồ: Chọn Gauge.
- Truy vấn PromQL:
Chúng ta sẽ sử dụng truy vấn rõ ràng và chính xác, tính toán dựa trên tổng bộ nhớ và bộ nhớ khả dụng.# (Tổng RAM - RAM khả dụng) / Tổng RAM * 100 (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 - Giải thích truy vấn:
node_memory_MemTotal_bytes: Lấy tổng dung lượng RAM của hệ thống.node_memory_MemAvailable_bytes: Lấy dung lượng RAM khả dụng cho các ứng dụng mới. Chỉ số này chính xác hơn làMemFree.- Truy vấn này hoạt động chính xác vì Prometheus tự động ghép cặp (vector matching) hai chỉ số
MemTotalvàMemAvailablecho cùng mộtinstance.
- Cấu hình Panel:
- Đặt Title là RAM Usage.
- Chọn Unit là Percent (0-100).
- Thiết lập Thresholds nếu bạn muốn cảnh báo bằng màu sắc.
- Nhấn Apply.
Xây dựng Panel giám sát Network
Panel 4: Network Traffic – Biểu đồ Time series
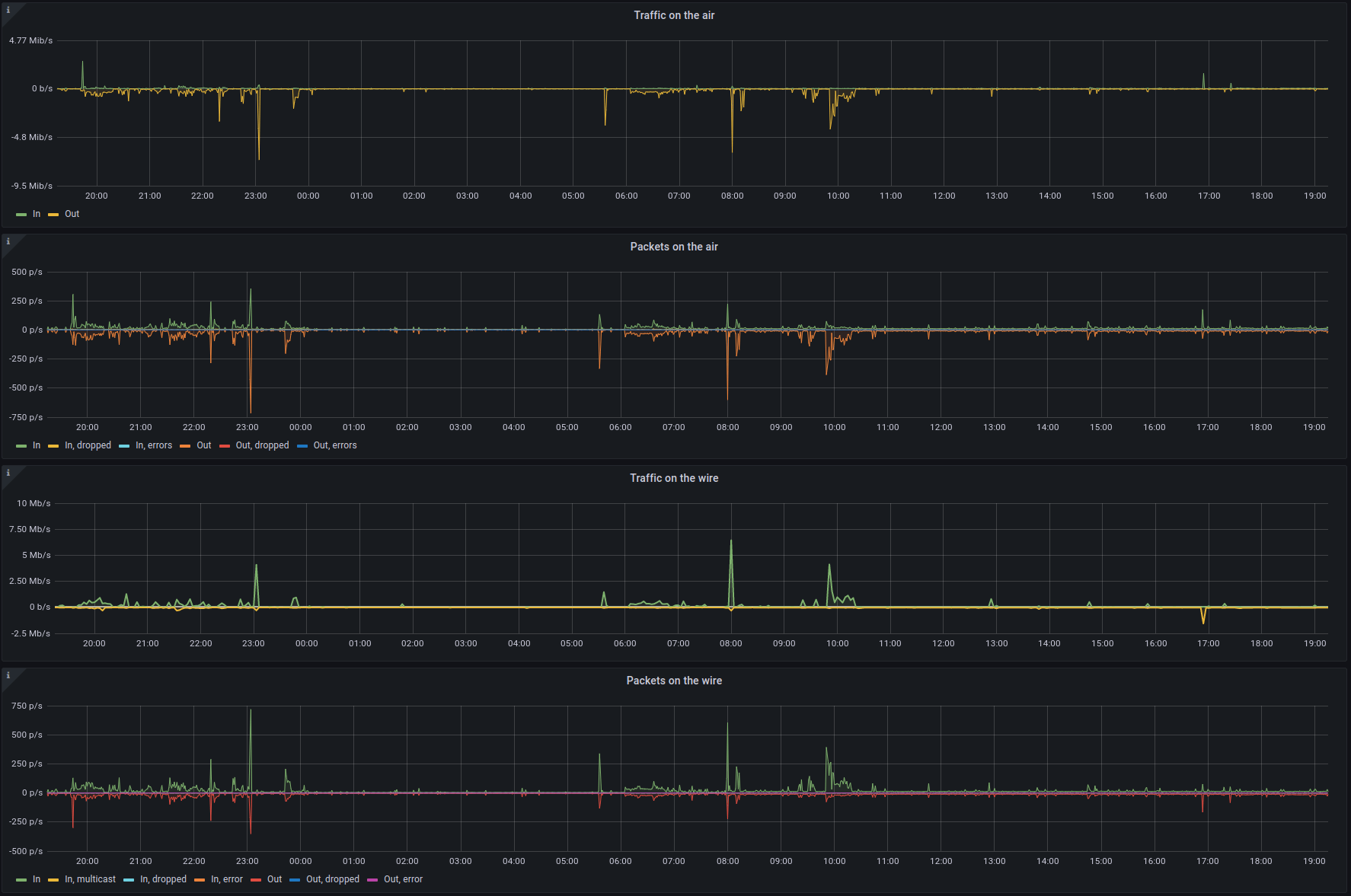
Biểu đồ giám sát lưu lượng mạng vào/ra
- Mục tiêu: Theo dõi đồng thời lưu lượng mạng đi vào (In) và đi ra (Out) trên một biểu đồ duy nhất.
- Loại biểu đồ: Chọn Time series.
- Truy vấn PromQL:
Chúng ta sẽ sử dụng hai truy vấn trong cùng một panel.- Query A (Lưu lượng vào):
# Tốc độ nhận dữ liệu (bytes/giây) rate(node_network_receive_bytes_total{device!="lo"}[5m]) - Nhấn nút + Add query để thêm truy vấn thứ hai.
- Query B (Lưu lượng ra):
Chúng ta sẽ dùng một mẹo nhỏ là nhân với -1 để biểu đồ hiển thị hướng xuống dưới, tạo cảm giác trực quan về dòng dữ liệu đi ra.# Tốc độ gửi dữ liệu (bytes/giây), nhân với -1 để đổi chiều rate(node_network_transmit_bytes_total{device!="lo"}[5m]) * -1
- Query A (Lưu lượng vào):
- Giải thích truy vấn:
{device!="lo"}: Điều kiện này để loại trừ interface “loopback”, là giao diện mạng nội bộ của máy mà chúng ta không cần giám sát.rate(): Chúng ta sử dụng hàmrate()để tính tốc độ trung bình trên mỗi giây. Nếu bạn muốn xem tổng lưu lượng mạng trong khoảng thời gian đó, bạn có thể dùng hàmincrease().
- Cấu hình Panel:
- Đặt Title là
Network Traffic (In/Out). - Trong Unit, chọn Data > Bytes/sec(SI).
- Để làm cho biểu đồ đẹp hơn, vào tab Overrides bên phải. Tạo một “override for fields with name” cho
Value #B(truy vấn B), và trong phần Graph styles > Transform, chọn Negative Y. Điều này sẽ đảm bảo trục Y luôn dương. - Nhấn Apply.
- Đặt Title là
Sau khi đã tạo xong các panel cơ bản, hãy nhấn vào biểu tượng đĩa mềm ở góc trên bên phải để lưu lại dashboard của bạn.
Nâng cao: Biến Dashboard trở nên chuyên nghiệp
Đây là những kỹ thuật sẽ nâng tầm dashboard của bạn, giúp nó trở nên linh hoạt và dễ quản lý hơn rất nhiều.
Sử dụng Biến (Variables) – Giám sát nhiều VPS trên một Dashboard
Nếu bạn có nhiều VPS, Variables là tính năng bắt buộc phải dùng. Grafana hỗ trợ nhiều loại biến, nhưng Query là loại linh hoạt nhất khi làm việc với Prometheus. Nó cho phép bạn tạo một menu dropdown để chuyển đổi xem dữ liệu giữa các VPS.
- Nhấp vào biểu tượng bánh răng Dashboard settings ⚙️ ở góc trên bên phải.
- Chọn menu Variables ở bên trái, sau đó nhấp Add new variable.
- Cấu hình biến:
- Name:
instance - Type:
Query - Label:
Instance(Tên hiển thị trên dashboard) - Data source: Chọn Prometheus
- Query:
label_values(up{job="node_exporter"}, instance)(Lấy danh sách tất cả các VPS có job là “node_exporter”) - Selection Options: Bật Multi-value và Include All option.
- Name:
- Nhấn Update để lưu.
Minh họa tính năng Variables (Biến)
Bây giờ, hãy quay lại các panel và cập nhật truy vấn để sử dụng biến này. Ví dụ, với panel CPU Usage:
- Truy vấn cũ:
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) - Truy vấn mới:
100 - (avg by (instance) (rate(node_cpu_seconds_total{instance=~"$instance", mode="idle"}[5m])) * 100)Hãy thêm
{instance=~"$instance"}vào tất cả các truy vấn của bạn.
Tổ chức Dashboard khoa học với Hàng (Rows)
Khi có nhiều panel, dashboard có thể trở nên lộn xộn. Rows giúp bạn nhóm các panel lại theo chức năng (ví dụ: nhóm CPU, nhóm RAM, nhóm Network).
Trên giao diện dashboard, nhấp vào nút Add và chọn Row. Một hàng mới sẽ được tạo ra. Bạn có thể đặt tên cho nó và kéo thả các panel liên quan vào bên dưới hàng đó. Các hàng có thể được thu gọn lại, giúp dashboard của bạn cực kỳ gọn gàng.
Gợi ý các Panel hữu ích khác để bạn thực hành
Với kiến thức vừa học, bạn hoàn toàn có thể tự xây dựng thêm các panel hữu ích khác. Dưới đây là một vài gợi ý và truy vấn để bạn bắt đầu.
Panel Disk Space Usage (%) – Biểu đồ Gauge
- Mục tiêu: Giám sát % dung lượng ổ đĩa đã sử dụng.
- PromQL:
100 - ((node_filesystem_avail_bytes{mountpoint="/"} * 100) / node_filesystem_size_bytes{mountpoint="/"}) - Nâng cấp: Biến
mountpointđộng
Để làm cho panel này mạnh mẽ hơn, bạn có thể tạo một biến để chọnmountpoint(phân vùng) muốn xem.- Vào Dashboard settings > Variables > Add new variable.
- Name:
mountpoint - Type:
Query - Query:
label_values(node_filesystem_avail_bytes{job="node_exporter", instance=~"$instance"}, mountpoint) - Lưu lại và cập nhật truy vấn của panel Disk Space:
100 - ((node_filesystem_avail_bytes{mountpoint=~"$mountpoint"} * 100) / node_filesystem_size_bytes{mountpoint=~"$mountpoint"})
Panel Server Uptime – Biểu đồ Stat
- Mục tiêu: Hiển thị thời gian hoạt động liên tục của server (tính bằng ngày).
- PromQL:
(time() - node_boot_time_seconds) / 86400 - Cấu hình: Chọn Unit là Time > days (d).
Câu hỏi thường gặp (FAQ)
1. Tại sao nên tự xây dựng dashboard thay vì import có sẵn?
Việc tự xây dựng dashboard giúp bạn có toàn quyền kiểm soát, hiểu sâu về từng chỉ số và dễ dàng tùy chỉnh, mở rộng hoặc sửa lỗi khi cần. Nó biến bạn từ người dùng thành người làm chủ công cụ, thay vì phụ thuộc vào một “hộp đen” có sẵn.
2. Làm thế nào để tính % CPU Usage trong PromQL?
Bạn có thể sử dụng truy vấn sau để tính toán % CPU đang hoạt động bằng cách lấy 100% trừ đi % CPU ở trạng thái nhàn rỗi: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100).
3. Khoảng thời gian [5m] trong hàm rate() có ý nghĩa gì?
Đây là khoảng thời gian (range vector) mà hàm rate() sẽ nhìn lại để tính toán tốc độ thay đổi trung bình. Khoảng thời gian này nên lớn hơn ít nhất 2-4 lần so với tần suất lấy mẫu (scrape_interval) của Prometheus để đảm bảo kết quả tính toán chính xác và mượt mà.
4. Làm sao để xem dữ liệu của nhiều VPS khác nhau trên cùng một dashboard?
Bạn có thể sử dụng tính năng Variables (Biến) trong Grafana. Bằng cách tạo một biến kiểu Query để lấy danh sách các instance (VPS), bạn sẽ có một menu dropdown để linh hoạt chuyển đổi hoặc hiển thị dữ liệu từ nhiều server trên cùng một giao diện.
5. Ngoài CPU, RAM, Network, tôi nên giám sát thêm chỉ số nào?
Một số chỉ số hữu ích khác bao gồm Disk Space Usage (dung lượng ổ đĩa sử dụng), System Load Average (tải trung bình hệ thống), và Server Uptime (thời gian hoạt động). Giám sát các chỉ số này giúp bạn có cái nhìn toàn diện hơn về “sức khỏe” của VPS.
Kết luận
Chúc mừng bạn! Bạn đã đi một chặng đường dài từ việc sử dụng một dashboard có sẵn đến việc tự tay xây dựng và làm chủ hoàn toàn công cụ của mình. Giờ đây, bạn không chỉ có một Dashboard giám sát VPS đẹp mắt, mà còn sở hữu kỹ năng và tư duy để tùy chỉnh, mở rộng nó theo bất kỳ nhu-cầu nào trong tương lai.
Đây là nền tảng vững chắc để bạn tiếp tục khám phá việc giám sát các dịch vụ khác như database, web server. Bước tiếp theo trên hành trình này là thiết lập các cảnh báo tự động, bạn có thể tham khảo Hướng dẫn cấu hình Alertmanager.
Hãy thử nghiệm và sáng tạo không ngừng. Chúc bạn thành công!
Tài liệu tham khảo









