Tự xây dựng AI Agent: Hướng dẫn cài đặt n8n trên VPS tích hợp DeepSeek
Bạn đang phải trả bao nhiêu tiền mỗi tháng cho hóa đơn Zapier hay Make.com? Khi hệ thống bắt đầu scale, các request tự động hóa tăng vọt lên hàng nghìn, thậm chí hàng chục nghìn task mỗi ngày, việc phụ thuộc vào các nền tảng SaaS Automation giống như việc bạn đang thuê một chiếc taxi để đi làm hàng ngày thay vì tự mua một chiếc xe. Không chỉ là câu chuyện bill API tăng phi mã vượt ngoài tầm kiểm soát, mà những vấn đề nhức nhối như rò rỉ dữ liệu nội bộ, IP bị block, hay API bị rate-limit bất thình lình cũng đủ khiến các developer và marketer mất ăn mất ngủ.
Đó là lý do mà xu hướng vận hành của năm 2026 đang dịch chuyển cực kỳ mạnh mẽ sang việc tự host hạ tầng AI Agent nội bộ. Bằng cách cài đặt n8n trên VPS và tích hợp bộ não DeepSeek, bạn hoàn toàn làm chủ một cỗ máy tự động hóa chạy 24/7 với chi phí rẻ đến bất ngờ. Bạn đã sẵn sàng biến một chiếc VPS Linux thô sơ thành một nhân viên số mẫn cán chưa? Liệu việc setup chuẩn production có thực sự phức tạp và dễ bị hacker dòm ngó như lời đồn? Hãy cùng xắn tay áo lên, mở terminal và đi thẳng vào thực chiến!
Đau đầu vì phí API cắt cổ của Zapier/Make? Đã đến lúc tự host AI Agent!
Sự rời bỏ các nền tảng SaaS Automation không phải là một phong trào nhất thời của giới công nghệ, mà nó xuất phát từ bài toán sống còn của mọi doanh nghiệp: Chi phí vận hành và Quyền kiểm soát hệ thống.
Các nền tảng đám mây này hoạt động theo mô hình tính phí dựa trên số lần chạy (per execution) hoặc số lượng tác vụ (tasks). Nếu bạn chỉ setup một luồng gửi vài email thông báo mỗi ngày, mọi thứ đều ổn. Nhưng hãy nhìn vào quy mô thực tế: giả sử bạn thiết lập một AI Agent đọc, phân tích, phân loại và phản hồi 500 email mỗi ngày, kết hợp thu thập dữ liệu từ 10 trang tin tức (RSS) và push bài tự động lên hệ thống mạng lưới WordPress. Khối lượng task khổng lồ này sẽ đốt sạch gói cước cao cấp nhất của bạn chỉ trong vỏn vẹn vài ngày.
Ngược lại, khi bạn chọn giải pháp cài đặt n8n trên VPS để thay thế Zapier, tiết kiệm chi phí và không giới hạn workflow, bạn sở hữu đặc quyền tối thượng: khả năng chạy vô hạn (unlimited workflows) với một mức phí cố định hàng tháng của server.
- Bài toán chi phí được giải quyết triệt để: Ở cường độ cao (ví dụ 500 – 1000 runs/ngày), nếu bạn kết hợp n8n self-hosted với DeepSeek API (nổi tiếng với mức giá siêu rẻ), tổng chi phí mỗi tháng của bạn (bao gồm tiền thuê VPS và tiền gọi LLM API) chỉ loanh quanh ở mức $15 – $30. Đây là một con số không tưởng nếu so với hóa đơn hàng trăm, thậm chí hàng ngàn đô la của các dịch vụ SaaS.
- Bảo mật dữ liệu (Data Privacy): Dữ liệu khách hàng, email nội bộ hay kịch bản marketing tuyệt mật của doanh nghiệp sẽ không bao giờ bị tuồn ra ngoài internet hay nằm phơi mình trên máy chủ của một bên thứ 3. Thậm chí, nếu bạn quyết định chạy Local AI bằng công cụ Ollama, bạn đạt tiêu chí zero API cost và bảo vệ quyền riêng tư tuyệt đối (Air-gapped AI).
- Kiểm soát Rate-limit và chống tấn công: Public webhooks của SaaS là một điểm yếu trí mạng. Nếu bị đối thủ dò ra và spam request liên tục, hệ thống của bạn sẽ bị sập hoặc tài khoản LLM của bạn sẽ bị trừ sạch tiền trong một đêm. Khi tự host trên VPS, bạn nắm quyền sinh sát: thiết kế hệ thống theo nhiều lớp bảo vệ, dùng Nginx làm proxy chặn các request rác, áp dụng rate limit IP, sử dụng xác thực (HMAC, Bearer Token), và thiết kế quy trình trong n8n fail fast (rẽ nhánh reject ngay ở node đầu tiên) trước khi request kịp gọi đến AI đắt tiền.

Tự cấu hình và cài đặt n8n trên VPS giúp doanh nghiệp gạt bỏ hoàn toàn nỗi lo chi phí leo thang theo số lượng task của SaaS.
Yêu cầu cấu hình VPS Linux chuẩn bài để gánh n8n và mô hình AI
Trước khi gõ những dòng lệnh đầu tiên, việc định cỡ (sizing) cho VPS là bước tiền đề không thể bỏ qua. Bạn không thể hy vọng chạy một cỗ máy AI mượt mà trên một server quá yếu, nhưng cũng chẳng tội gì ném tiền qua cửa sổ cho những tài nguyên thừa thãi.
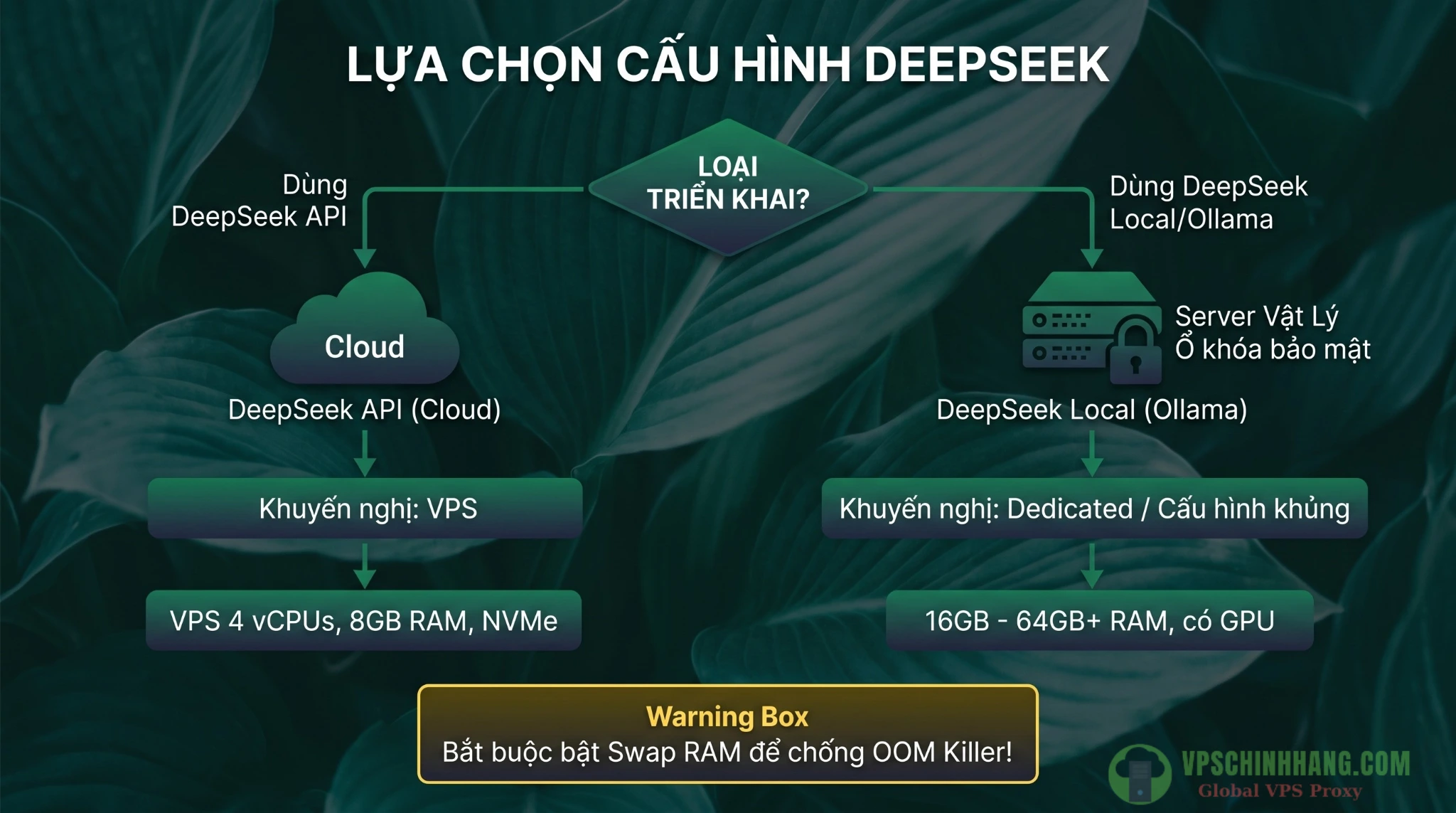
Tùy thuộc vào việc bạn gọi DeepSeek qua API hay chạy Local (Ollama) mà cấu hình RAM và CPU của VPS sẽ khác biệt rất lớn.
Kịch bản dùng DeepSeek qua API (lựa chọn tối ưu cho hiệu năng/chi phí)
Trong kịch bản này, n8n chỉ đóng vai trò làm trạm điều phối trung chuyển dữ liệu. Nó nhận data, format lại, gọi API ra ngoài (DeepSeek xử lý tính toán nặng trên cloud của họ), và nhận kết quả trả về.
- Tối thiểu: 2 vCPUs, 4GB RAM và 20GB SSD (Ưu tiên NVMe để tốc độ đọc/ghi database nhanh hơn). Đây là mức đủ để khởi chạy production nhỏ gọn, cá nhân.
- Mức nâng cao (Khuyên dùng): 4 vCPUs, 8-12GB RAM. Tại sao lại cần RAM nhiều hơn? Vì mỗi khi một execution chạy và gọi AI Agent xử lý lượng text lớn (như đọc nguyên một file log hoặc bài báo dài), Node.js sẽ cần thêm khoảng 200MB – 500MB+ RAM để lưu trữ context (bộ nhớ ngữ cảnh tạm thời) cho workflow đó. Nếu có 10 workflow chạy đồng thời, RAM sẽ bị ngốn rất nhanh.
Kịch bản chạy DeepSeek Local (Ollama) để bảo mật 100%
Nếu bạn muốn cài đặt Ollama trên VPS Linux để tự chạy Local AI (như DeepSeek, Llama 3) một cách riêng tư và an toàn mà không cần kết nối ra ngoài internet, yêu cầu RAM và CPU sẽ tăng vọt:
- Đối với các model rút gọn (distilled models) nhẹ nhàng như DeepSeek-R1 phiên bản 7B hoặc 14B: Cần VPS có tối thiểu 8-16GB RAM. Nếu tài chính cho phép, một VPS có kèm GPU nhẹ sẽ giúp tốc độ gen chữ nhanh hơn gấp nhiều lần, nếu không, CPU sẽ phải gồng gánh toàn bộ phép toán ma trận, dẫn đến việc %CPU luôn ở mức 100% khi AI hoạt động.
- Đối với model cỡ lớn (như DeepSeek-R1 80GB full): Bạn đừng mơ tới việc chạy trên VPS giá rẻ. Bạn sẽ cần tối thiểu một Dedicated Server với 64GB RAM hệ thống và 16GB VRAM (GPU) để chạy mượt ở tốc độ 1-2 token/giây.
Bí kíp sinh tồn: Hiểu về OOM Killer và tối ưu Swap
Trong môi trường Linux, có một sát thủ thầm lặng mang tên OOM Killer (Out-Of-Memory Killer). Khi server cạn kiệt RAM vật lý, hệ điều hành sẽ tự động đi tìm và bắn tỉa (kill) các tiến trình ngốn RAM nhất để cứu nguy cho hệ thống. Thường thì nạn nhân đầu tiên chính là tiến trình Node.js của n8n hoặc Ollama. Hậu quả là workflow của bạn ngừng hoạt động giữa chừng và trình duyệt hiện lỗi 502 Bad Gateway.
- Kinh nghiệm thực chiến: Giải pháp rẻ tiền, hiệu quả và bắt buộc phải làm ngay khi mua VPS là bật RAM ảo (Swap). Việc tạo một swap file (khoảng 4GB đến 8GB) trên ổ cứng NVMe sẽ tạo ra một vùng đệm dự phòng. Mặc dù tốc độ đọc/ghi của Swap chậm hơn RAM thật, nhưng nó giúp VPS sống sót ngoạn mục qua những đợt bùng nổ (spike) request bất thình lình mà không bị crash hệ thống.
Thực chiến 3 bước cài đặt n8n trên VPS bằng Docker Compose (bản production)
Rất nhiều tutorial hướng dẫn dạng mì ăn liền trên mạng bảo bạn chạy n8n bằng SQLite để cho lẹ. Đừng làm vậy! SQLite mặc định cực kỳ dễ bị khóa dữ liệu (database locked) khi bạn có trên 10 active workflows chạy song song hoặc nhận một đợt webhook ồ ạt. Ở môi trường Production thực tế, nơi dữ liệu là tiền bạc, chúng ta bắt buộc phải dùng kiến trúc kết hợp PostgreSQL.
Dưới đây là hướng dẫn cài đặt n8n trên VPS Ubuntu 22.04/24.04 LTS theo chuẩn enterprise.
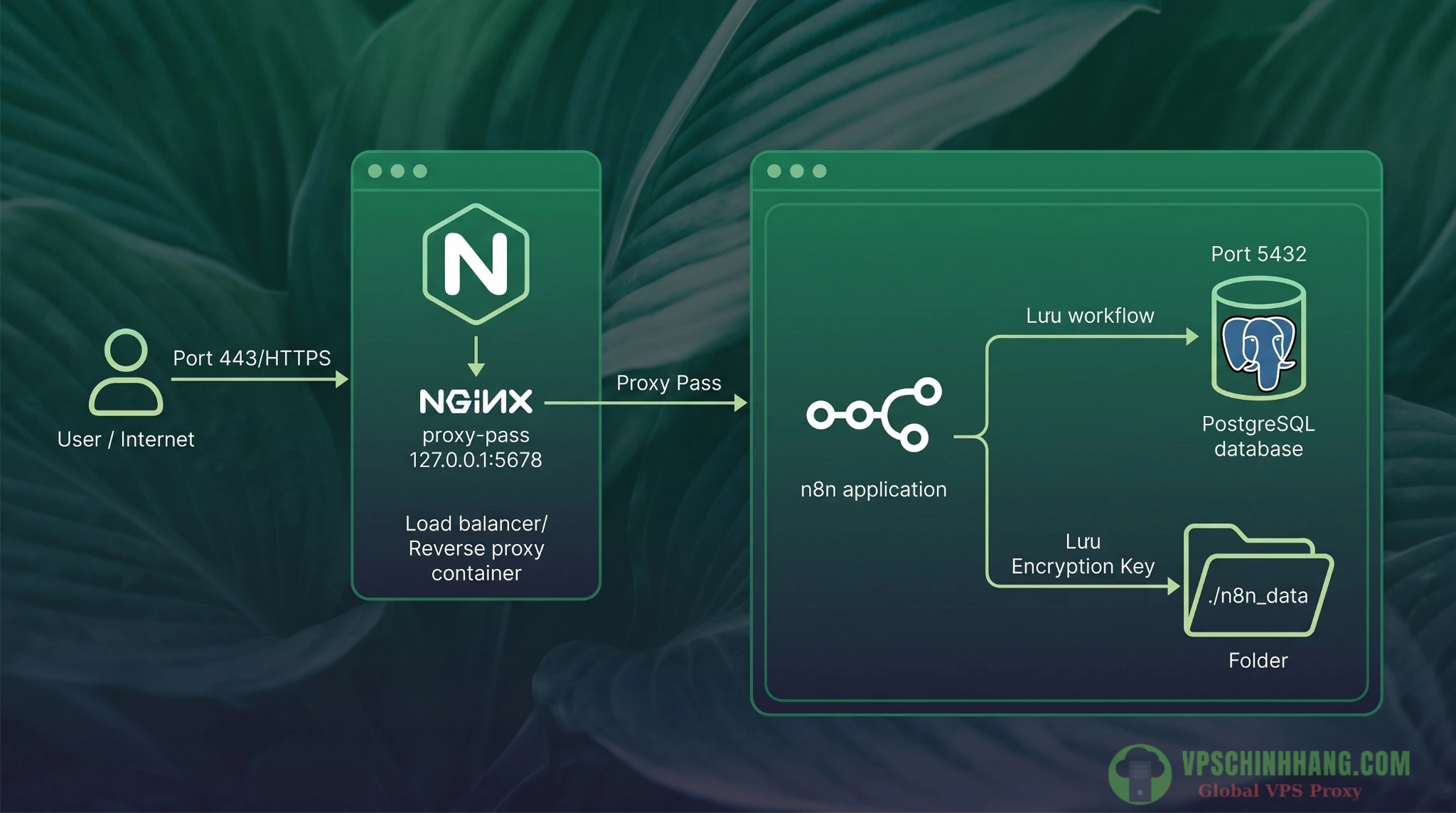
Mô hình cài đặt n8n chuẩn Production sử dụng PostgreSQL làm Database và Nginx làm Reverse Proxy để đảm bảo an toàn tuyệt đối.
Bước 1: Setup môi trường Docker và cấu trúc thư mục project
Đầu tiên, hãy SSH vào VPS bằng quyền root hoặc user có quyền sudo. Cập nhật các package hệ thống để vá lỗi bảo mật, sau đó tham khảo các bước cài đặt Docker trên VPS Ubuntu dành cho người mới bắt đầu:
Cập nhật hệ thống:
sudo apt update && sudo apt upgrade -yTải và chạy script cài đặt Docker chính thức:
curl -fsSL https://get.docker.com | shCài đặt plugin Docker Compose v2:
sudo apt install docker-compose-plugin -yTiếp theo, hãy tạo một không gian làm việc sạch sẽ, gọn gàng để lưu trữ dữ liệu an toàn. Tuyệt đối không để data vương vãi ở thư mục root.
Tạo không gian làm việc và di chuyển vào thư mục dự án:
mkdir -p ~/n8n-ai-agent
cd ~/n8n-ai-agentTạo các thư mục lưu trữ vĩnh viễn (persistent volumes):
mkdir -p n8n_data postgres_dataQUAN TRỌNG: Phân quyền cho n8n user. Node.js user bên trong container n8n mặc định có UID là 1000. Nếu không chạy lệnh này, n8n sẽ báo lỗi EACCES (không có quyền ghi file):
sudo chown -R 1000:1000 n8n_dataBước 2: Viết file docker-compose.yml tối ưu hiệu năng
Hãy dùng text editor (như nano hoặc vim) để tạo file orchestration:
nano docker-compose.ymlDán cấu hình chi tiết dưới đây vào. Hãy chú ý đọc kỹ các comment giải thích của mình, đây là những kinh nghiệm xương máu khi deploy:
version: '3.8'
services:
postgres:
image: postgres:16-alpine # Dùng bản 16 Alpine cực kỳ ổn định và siêu nhẹ
container_name: n8n-postgres
restart: always
environment:
- POSTGRES_USER=n8n
- POSTGRES_PASSWORD=your_super_strong_password_here
- POSTGRES_DB=n8n
volumes:
- ./postgres_data:/var/lib/postgresql/data
healthcheck:
test: ['CMD-SHELL', 'pg_isready -h localhost -U n8n -d n8n']
interval: 5s
timeout: 5s
retries: 10
n8n:
image: docker.n8n.io/n8nio/n8n:latest
container_name: n8n-app
restart: always
environment:
# Khai báo sử dụng Postgres
- DB_TYPE=postgresdb
- DB_POSTGRESDB_DATABASE=n8n
- DB_POSTGRESDB_HOST=postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_USER=n8n
- DB_POSTGRESDB_PASSWORD=your_super_strong_password_here
# Cấu hình domain và webhook
- N8N_HOST=n8n.yourdomain.com
- N8N_PORT=5678
- N8N_PROTOCOL=https
- NODE_ENV=production
- WEBHOOK_URL=https://n8n.yourdomain.com/
- GENERIC_TIMEZONE=Asia/Ho_Chi_Minh
# Giới hạn dung lượng log để tránh đầy ổ cứng
- N8N_DIAGNOSTICS_ENABLED=false
- EXECUTIONS_DATA_PRUNE=true
- EXECUTIONS_DATA_MAX_AGE=168 # Xóa log sau 7 ngày (168 giờ)
ports:
# CHÚ Ý: Map vào 127.0.0.1 để giấu port khỏi internet, chỉ cho Nginx gọi vào
- "127.0.0.1:5678:5678"
volumes:
- ./n8n_data:/home/node/.n8n
depends_on:
postgres:
condition: service_healthy # Bắt buộc n8n phải đợi Postgres boot xongTại sao file config này đáng giá ngàn vàng?
- Healthcheck & Depends_on: Database cần thời gian khởi động (khởi tạo tables, allocate memory). Nếu n8n khởi động nhanh hơn và cố kết nối vào Postgres khi nó chưa sẵn sàng, n8n sẽ crash ngay lập tức. Thiết lập
condition: service_healthyép n8n phải ngoan ngoãn chờ PostgreSQL báo sẵn sàng thông qua lệnhpg_isreadyrồi mới được chạy. - Map Volume toàn diện: Khai báo
./n8n_data:/home/node/.n8nlà cực kỳ quan trọng. Dù đã dùng PostgreSQL để lưu workflow, nhưng n8n vẫn ghi các file khóa mã hóa (encryption key) ra thư mục cục bộ. Nếu bỏ sót volume này, mỗi lần bạn xóa container để update phiên bản mới, n8n sẽ tạo ra encryption key mới, đồng nghĩa với việc bạn sẽ mất sạch mật khẩu của các luồng tích hợp (credentials) vĩnh viễn.
Lưu file lại và khởi chạy toàn bộ hệ thống ở chế độ background:
docker compose up -dBạn có thể kiểm tra trạng thái bằng lệnh docker ps.
Bước 3: Cấu hình Nginx Reverse Proxy & SSL (yếu tố sống còn)
Không bao giờ để lộ port 5678 thẳng ra internet. Bạn cần tham khảo cách định cấu hình Nginx làm Proxy ngược trên VPS Linux Ubuntu để điều phối traffic và cấp chứng chỉ bảo mật SSL.
Cài đặt Nginx và Certbot (công cụ lấy SSL Let’s Encrypt tự động):
sudo apt install nginx certbot python3-certbot-nginx -yTạo file config Nginx ảo cho domain của bạn:
sudo nano /etc/nginx/sites-available/n8nDán cấu hình sau (nhớ thay n8n.yourdomain.com bằng tên miền thực của bạn):
server {
server_name n8n.yourdomain.com;
location / {
proxy_pass http://127.0.0.1:5678;
# BẮT BUỘC BẬT WEBSOCKET CHO N8N
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}Kinh nghiệm đau thương: Nếu bạn quên 3 dòng cấu hình WebSocket (Upgrade, Connection), giao diện Editor UI của n8n trên trình duyệt sẽ bị lỗi hiển thị. Nó không thể hiển thị real-time tiến trình workflow đang chạy và liên tục nháy đỏ báo lỗi Connection lost.
Kích hoạt site và xin cấp SSL.
Tạo symlink để enable site:
sudo ln -s /etc/nginx/sites-available/n8n /etc/nginx/sites-enabled/Kiểm tra xem file config có lỗi cú pháp không:
sudo nginx -tChạy Certbot lấy SSL:
sudo certbot --nginx -d n8n.yourdomain.comSau khi hoàn tất, hãy truy cập https://n8n.yourdomain.com để thiết lập tài khoản Admin đầu tiên.
Bơm trí thông minh DeepSeek vào hệ thống n8n
Hạ tầng nền móng đã vững chắc, bây giờ là lúc chúng ta thổi hồn vào hệ thống bằng việc kết nối n8n với mô hình DeepSeek.
Cách 1: Tích hợp DeepSeek qua Cloud API (nhanh, nhẹ, tiết kiệm)
DeepSeek rất thông minh khi thiết kế API của họ tương thích 100% với định dạng API SDK của OpenAI. Điều này giúp các developer tích hợp hệ thống cực kỳ dễ dàng mà không cần phải viết lại code hay chờ đợi plugin riêng.
- Trong giao diện workflow của n8n, bạn không cần phải cất công tìm node DeepSeek. Hãy mở panel bên phải và kéo node
OpenAI Chat Modelvào canvas. - Tại mục Credentials, click tạo mới một Credential kiểu OpenAI.
- Dán API Key bạn vừa tạo từ trang platform của DeepSeek vào mục API Key.
- Ở phần thiết lập Base URL (thường bị ẩn trong mục Advanced hoặc tùy chỉnh), hãy đổi URL mặc định của OpenAI thành endpoint của DeepSeek.(Lưu ý cực kỳ quan trọng: Tùy thuộc vào phiên bản n8n hiện tại, bạn có thể điền Base URL là https://api.deepseek.com/v1 hoặc https://api.deepseek.com nếu n8n báo lỗi dư chữ /v1/v1 do tự động nối thêm hậu tố. Hãy test thử cả 2 để xem n8n của bạn đang xử lý url như thế nào).
- Về cấu hình Model Name, hãy chuyển sang dạng nhập biểu thức tuỳ biến (expression) và gõ thủ công tên model là
deepseek-chat(phiên bản V4 dùng cho mọi tác vụ) hoặcdeepseek-reasoner(phiên bản R1 siêu suy luận).
Cách 2: Kết nối với Local LLM (Ollama) an toàn tuyệt đối
Nếu bạn triển khai cài Ollama ngay trên chính VPS này (hoặc một server nội bộ khác), bạn sẽ dùng node Ollama Chat Model trong n8n.
- Điểm nghẽn kỹ thuật người mới hay gặp: Rất nhiều bạn điền URL kết nối là
http://localhost:11434và bị n8n ném ra lỗi Connection refused. Lý do là gì? Vì n8n đang chạy cô lập trong container Docker, thuật ngữlocalhostđối với nó hiểu là mạng loopback bên trong chính container đó, chứ không phải máy chủ gốc (VPS) nơi Ollama đang chạy. - Cách giải quyết: Để vượt rào an toàn, hãy đổi URL thành địa chỉ IP nội bộ cấp bởi Docker (thường là
172.17.0.1). Một cách thanh lịch hơn là dùng hostnamehost.docker.internal(nhớ khai báo thêmextra_hostsvào trong filedocker-compose.ymlcủa n8n) để container có thể gọi ra ngoài host lấy dữ liệu LLM một cách trơn tru, không cần đi vòng ra mạng Internet công cộng.
2 Workflow AI Agent thực tế giúp developer/marketer nhàn hạ
Có hệ thống trong tay, sức mạnh thực sự nằm ở cách bạn thiết kế các luồng tự động hóa (workflow) tạo ra dòng tiền và giải phóng thời gian.
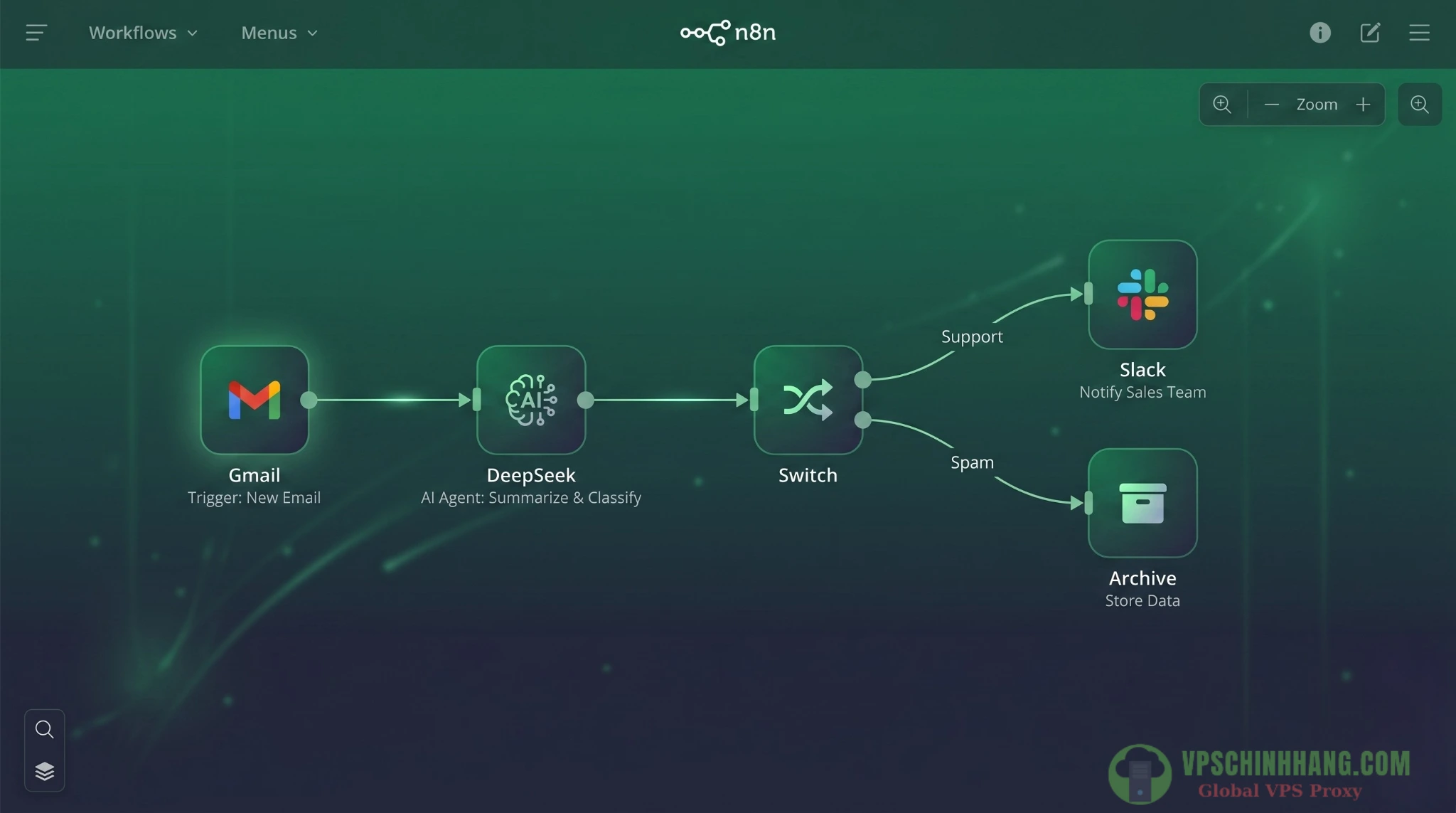
Một workflow n8n kết hợp DeepSeek điển hình giúp doanh nghiệp tự động hóa hoàn toàn khâu sàng lọc và phân phối email CSKH.
Workflow 1: AI Agent Triage Inbox (đọc, phân loại và xử lý email)
Bạn có chán ngấy việc mỗi sáng phải mở hộp mail support ra để căng mắt phân loại xem email nào là khách hàng phàn nàn, email nào hỏi giá mua hàng, và email nào là spam rác?
- Trigger: Khởi đầu quy trình bằng Node
Gmail Trigger(kết nối qua chuẩn OAuth2 bảo mật hoặc IMAP) để fetch các email mới chưa đọc. - AI Agent Node (Bộ não): Đưa toàn bộ nội dung text của email vào node
AI Agent. Mớm cho nó một system prompt sắc bén: “Bạn là một trợ lý ảo CSKH xuất sắc. Hãy đọc email dưới đây, lọc bỏ những đoạn chữ ký không cần thiết, tóm tắt ý chính trong 1 câu ngắn gọn, và gán nhãn nó thuộc 1 trong 3 loại chính xác: Hỗ Trợ Kỹ Thuật, Hỏi Giá Bán, hoặc Spam”. - Structured Output Parser (Kỷ luật dữ liệu): AI rất hay nói nhiều (hallucination). Bạn phải ép DeepSeek trả về chuẩn định dạng JSON để bóc tách trường nhãn chính xác tuyệt đối mà máy tính có thể đọc được (ví dụ:
{"category": "spam"}). - Switch Node (Rẽ nhánh logic): Đây là nơi phép màu xảy ra. Dựa trên giá trị của trường “category”:
- Nếu là
Spam-> Rẽ nhánh vào Node Gmail thứ hai, ra lệnh tự động đánh dấu Đã Đọc và đẩy vào mục Archive. Không cần con người bận tâm. - Nếu là
Hỏi Giá Bán-> Rẽ nhánh vào Node HTTP Request (gọi Slack API) hoặc Telegram Node, đẩy một tin nhắn alert cho team Sales ngay lập tức với nội dung tóm tắt của AI và thông tin liên hệ của khách hàng. Chốt đơn tính bằng giây!
- Nếu là
Workflow 2: Cỗ máy Auto-Blogging (trích xuất RSS, viết SEO và push WordPress)
- Khởi động chu kỳ: Dùng
RSS Feed Trigger(hoặc Schedule Trigger kết hợp Node HTTP GET) để bóc tách XML tin tức công nghệ từ các site uy tín trên thế giới theo chu kỳ mỗi 6 giờ/lần. - Sàng lọc & Xào nấu: Đưa dữ liệu qua
AI Agent(DeepSeek) để loại bỏ tin rác/tin trùng lặp. Cung cấp bộ keyword của bạn và yêu cầu AI viết lại (rewrite) bài viết thành phiên bản tiếng Việt chuẩn SEO. Quan trọng nhất: Yêu cầu AI format định dạng bài viết bằng HTML (bao gồm thẻ<h2>,<h3>, thẻ list<ul>và bôi đậm<strong>các keyword). - HTTP Request Node (Bắn lên WordPress): Sử dụng method
POSTđể bắn cục dữ liệu HTML từ kết quả AI trực tiếp vào API tạo bài viết của mạng lưới vệ tinh WordPress (https://yourblog.com/wp-json/wp/v2/posts). - Kinh nghiệm sống còn về WP REST API: Tuyệt đối, không bao giờ truyền user và mật khẩu admin gốc của bạn vào header Authorization (Basic Auth). Hãy đăng nhập vào trang cá nhân (Profile) trong dashboard WordPress, kéo xuống dưới tạo một Application Password (Mật khẩu ứng dụng) dành riêng cho bot n8n. Nếu hệ thống n8n có bị lộ lọt, bạn chỉ cần 1 click thu hồi (revoke) mật khẩu ứng dụng này là website của bạn vẫn an toàn vô sự.
Lưu ý sống còn về mạng, bảo mật và vận hành
Làm hệ thống để giải phóng sức lao động, đừng ngây thơ biến nó thành lỗ hổng để hacker biến máy chủ của bạn thành công cụ đào coin hay tham gia mạng botnet.
Cái bẫy UFW Firewall và cơ chế chọc thủng của Docker
Khuyến cáo bảo mật cơ bản nhất cho mọi máy chủ là tham khảo hướng dẫn cấu hình UFW Ubuntu để làm chủ tường lửa VPS trong năm 2025 nhằm đóng toàn bộ các port nhạy cảm. Bạn đã cẩn thận thiết lập đóng port 5678 (của n8n) và 11434 (của Ollama). Bạn tự tin gõ lệnh sudo ufw status và thấy mọi thứ đã được báo Action: DENY.
Tuy nhiên, bạn đã bị lừa!
Nếu bạn dùng lệnh docker với cờ -p 5678:5678 hoặc -p 11434:11434 (định tuyến mặc định), Docker engine có đặc quyền thao tác trực tiếp vào iptables cốt lõi của Linux. Nó sẽ tự động chọc thủng lớp bảo vệ UFW và phơi bày ứng dụng của bạn ra dải mạng 0.0.0.0 toàn cầu. Đây chính xác là nguyên nhân kỹ thuật khiến hàng trăm ngàn máy chủ AI Local bị hacker thâm nhập, lợi dụng quyền Tool-Calling của AI để thực thi mã độc từ xa.
Cách khắc phục:
- Như mình đã nhấn mạnh trong file
docker-compose.ymlở bước cài đặt, bạn BẮT BUỘC phải ánh xạ rõ ràng địa chỉ IP localhost cục bộ:127.0.0.1:5678:5678. Lúc này, port 5678 chỉ lắng nghe ở môi trường bên trong máy chủ. Nginx (lắng nghe hợp pháp ở port 443 công khai) sẽ làm nhiệm vụ bảo vệ và proxy traffic vào bên trong. Kẻ tấn công quét từ bên ngoài sẽ không thấy bất kỳ dấu vết nào của n8n hay Ollama. - Để giám sát xem có IP rác nào đang cố tình rà quét máy chủ của bạn không, bạn nên bật Log cho UFW bằng lệnh
sudo ufw logging on. Bạn có thể theo dõi file log tại/var/log/ufw.logđể ban (cấm) các IP có dấu hiệu khả nghi.
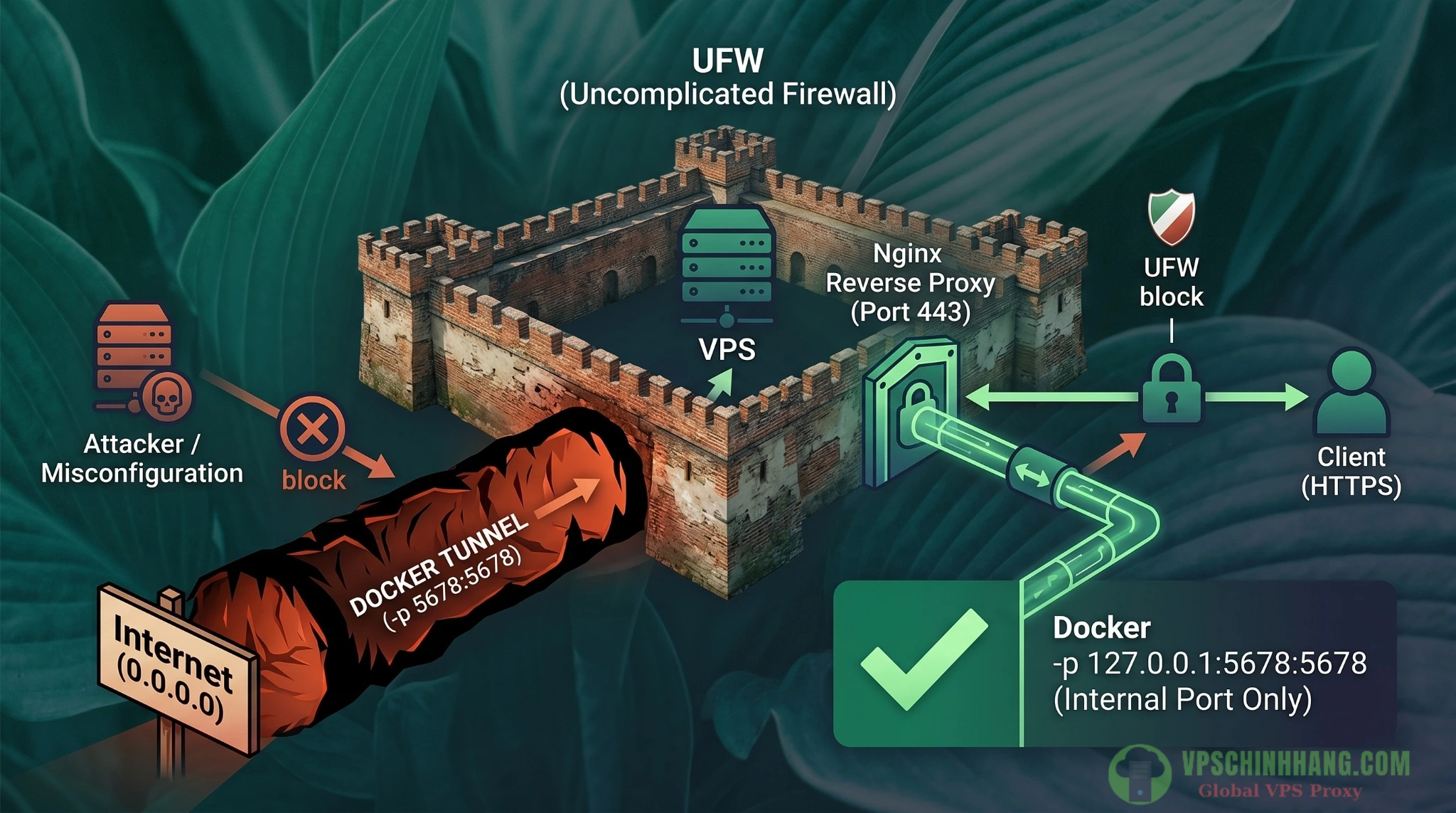
Sai lầm phổ biến khi map port Docker khiến UFW Firewall bị chọc thủng, tạo lỗ hổng cho hacker tấn công máy chủ AI.
Proxy Timeout cho tác vụ AI nặng
Khi dùng Nginx làm proxy ngược cho các mô hình AI Local (đặc biệt là Ollama) hay kể cả khi gọi các Webhook trả kết quả chậm, hãy nhớ rằng mô hình lớn cần thời gian để suy nghĩ (reasoning) và gen chữ. Timeout mặc định của Nginx thường rất ngắn, chỉ 60 giây. Quá 60 giây mà không thấy data phản hồi, Nginx sẽ tự cắt đứt kết nối và ném vào mặt bạn lỗi 504 Gateway Timeout, mặc dù mô hình AI bên dưới vẫn đang hì hục cày cuốc.
Để workflow chạy trơn tru với các task nặng, hãy thêm các cấu hình timeout này vào block location / của file Nginx:
proxy_read_timeout 600s;
proxy_connect_timeout 600s;
proxy_send_timeout 600s;
proxy_buffering off;Đặc biệt, dòng proxy_buffering off; đóng vai trò rất quan trọng nếu bạn dùng streaming. Nó giúp giao diện của bạn nhận được phản hồi mượt mà từng chữ một giống hệt như khi dùng ChatGPT, thay vì việc Nginx cố gắng giữ toàn bộ văn bản trong bộ nhớ đệm rồi mới nôn ra một cục khổng lồ.
Câu hỏi thường gặp (FAQ)
1. Phiên bản n8n tự host (Self-hosted) có bị giới hạn tính năng hay số lượng task không?
Không. Bản n8n Community self-hosted hoàn toàn miễn phí và không giới hạn số lượng workflow hay số task thực thi. Bạn chỉ trả chi phí cố định cho tài nguyên phần cứng của VPS.
2. Khi cài đặt n8n trên VPS, nên chọn DeepSeek API hay chạy DeepSeek Local qua Ollama?
Nếu VPS dưới 8GB RAM: Dùng DeepSeek API (chi phí cực rẻ, nhẹ máy, xử lý nhanh). Nếu VPS trên 16GB RAM và cần bảo mật dữ liệu tuyệt đối: Chạy DeepSeek Local qua Ollama.
3. Tại sao giao diện n8n Editor liên tục báo lỗi nhấp nháy Connection lost?
Do cấu hình Nginx Reverse Proxy của bạn thiếu các dòng kích hoạt WebSocket. Hãy bổ sung proxy_set_header Upgrade $http_upgrade; và proxy_set_header Connection "upgrade"; vào file config Nginx là xử lý được ngay.
4. Sửa lỗi 504 Gateway Timeout khi DeepSeek R1 mất quá nhiều thời gian để suy nghĩ như thế nào?
Thêm dòng proxy_read_timeout 600s; và proxy_buffering off; vào block location / trong cấu hình Nginx để tăng thời gian chờ và kích hoạt tính năng stream dữ liệu (gen chữ đến đâu hiển thị đến đó).
5. Làm sao để kiểm tra xem Docker có đang chọc thủng tường lửa UFW của VPS hay không?
Chạy lệnh sudo ufw status. Nếu bạn thấy đóng port nhưng vẫn truy cập được port đó từ một thiết bị ngoài dải mạng, nghĩa là Docker đã bypass UFW. Hãy sửa file docker-compose.yml thành -p 127.0.0.1:5678:5678 để vá lỗ hổng.
6. Kết nối n8n với WordPress REST API bằng cách nào để không bị lộ mật khẩu Admin?
Vào Dashboard WordPress -> Thành viên (Profile của bạn) -> Kéo xuống mục Mật khẩu ứng dụng (Application Passwords) để tạo một token riêng cho n8n. Tuyệt đối không dùng mật khẩu đăng nhập gốc.
Kết luận
Việc tự cài đặt n8n trên VPS và tích hợp bộ não DeepSeek AI Agent không chỉ là một bài thực hành kỹ thuật hay một thủ thuật công nghệ đơn thuần. Đó là bước chuyển mình chiến lược để bạn thực sự sở hữu, nắm giữ và làm chủ một hạ tầng tự động hóa quy chuẩn Enterprise của năm 2026. Bằng cách kết hợp kiến trúc PostgreSQL mạnh mẽ, am hiểu quản lý resource chặt chẽ và thiết lập Nginx/UFW an toàn vô khuyết, bạn đã loại bỏ hoàn toàn sự lệ thuộc vào các nền tảng SaaS đắt đỏ, bảo vệ 100% dữ liệu kinh doanh cốt lõi của mình.
Tuy nhiên, một cỗ máy tự động hóa chỉ phát huy hết 100% sức mạnh khi nó được đặt trên một nền móng vững chắc. Hệ thống càng phức tạp, xử lý khối lượng tác vụ AI lớn, phần cứng bên dưới càng phải bền bỉ và có tốc độ đọc ghi vượt trội. Nếu bạn đang tìm kiếm một nền tảng hạ tầng chịu tải tốt, uptime cao và không phải nơm nớp lo sợ OOM Killer ghé thăm phá đám, hãy tham khảo ngay các gói thuê VPS hiệu năng cao tích hợp ổ cứng NVMe chuyên biệt của chúng tôi. Hạ tầng mạng mạnh mẽ chính là chìa khóa vàng để AI Agent của bạn vận hành trơn tru, mang lại lợi nhuận 24/7!
Tài liệu tham khảo
- GitHub – ZenPloy-cloud/n8n-docker-production: Production-ready n8n Docker Compose configs with optimized resource limits for 1vCPU/4GB, 2vCPU/8GB, and 4vCPU/16GB servers. Main & queue modes included. · GitHub
- n8n Hosting Documentation and Guides | n8n Docs
- Ollama Security Risk: Why 175K Servers Exposed [2026] | QWE AI Academy