Giám sát Kubernetes trên K3s: Tối ưu Prometheus & Grafana cho VPS (Tránh OOMKilled)
Trong kỷ nguyên chuyển đổi số, việc hiện đại hóa hạ tầng từ các máy chủ ảo (VPS) đơn lẻ sang công nghệ Container là bước đi tất yếu để đảm bảo khả năng mở rộng linh hoạt. Đối với các doanh nghiệp vừa và nhỏ (SMBs) hoặc các hệ thống Edge Computing, K3s (Lightweight Kubernetes) đã trở thành tiêu chuẩn vàng nhờ tính gọn nhẹ, đóng gói toàn bộ sức mạnh của Kubernetes vào một binary duy nhất dưới 40MB.
Nếu bạn chưa có Cluster, hãy tham khảo bài viết Cài đặt Kubernetes nhẹ (K3s) trên VPS Linux: Giải pháp Orchestration tối ưu để thiết lập hạ tầng trước khi đi vào phần giám sát này.
Tuy nhiên, sự chuyển dịch này mang lại một thách thức khổng lồ về mặt vận hành: “Điểm mù” giám sát (Monitoring Blind-spots).
Các SysAdmin thường gặp tình huống trớ trêu: VPS vẫn báo trạng thái “xanh” (CPU thấp, RAM trống), nhưng ứng dụng bên trong Container lại hoạt động chập chờn, phản hồi chậm hoặc thậm chí khởi động lại liên tục. Các công cụ giám sát truyền thống như Zabbix, Nagios hay lệnh htop trở nên vô hiệu vì chúng chỉ nhìn thấy lớp vỏ bọc bên ngoài (Host OS) mà không thể thấu hiểu trạng thái sức khỏe của từng Pod, Service hay Ingress bên trong.
Bài viết này là cẩm nang kỹ thuật chuyên sâu, hướng dẫn bạn xây dựng hệ thống giám sát Kubernetes toàn diện bằng Kube-Prometheus-Stack trên nền tảng K3s. Nội dung được tối ưu hóa đặc biệt cho môi trường VPS hạn chế tài nguyên, giải quyết triệt để các vấn đề tương thích bộ nhớ đặc thù và tuân thủ các thực hành tốt nhất (Best Practices) về vận hành.
Tại sao cần nâng cấp từ giám sát VPS sang giám sát Kubernetes?
Để làm chủ hệ thống, trước tiên bạn cần thay đổi tư duy từ “Quản lý Máy chủ” sang “Quản lý Dịch vụ”. Trong môi trường Kubernetes, tài nguyên không còn là tĩnh mà là động và được quản lý qua các cơ chế phức tạp.
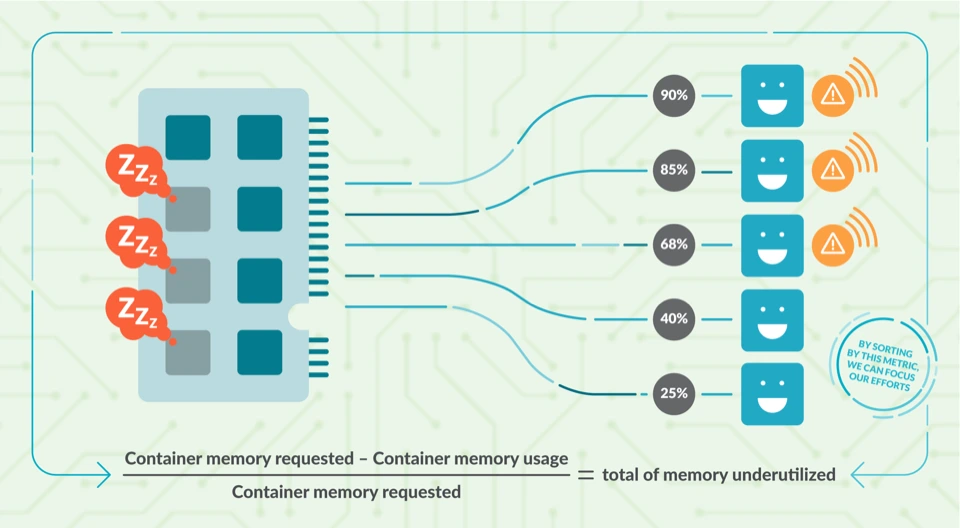
Minh họa sự chênh lệch giữa tài nguyên yêu cầu (Requested) và thực tế sử dụng (Usage), nguyên nhân chính gây lãng phí tài nguyên trên VPS.
OOMKilled – Kẻ sát thủ thầm lặng
Trên VPS truyền thống, khi hết RAM, hệ điều hành sẽ treo hoặc kích hoạt OOM Killer ngẫu nhiên. Trong Kubernetes, mỗi Pod được cấp một hạn mức (Limit). Nếu ứng dụng Java hoặc Node.js của bạn rò rỉ bộ nhớ và vượt quá giới hạn này, Kubernetes sẽ thẳng tay “giết” (Kill) Pod đó ngay lập tức, dù VPS của bạn vẫn còn hàng chục GB RAM trống. Chỉ có hệ thống giám sát Kubernetes chuyên dụng mới có thể theo dõi chỉ số container_memory_working_set_bytes và cảnh báo bạn trước khi sự cố xảy ra.
Vấn đề này thường bị nhầm lẫn với việc quá tải hệ thống, chi tiết cách xử lý bạn có thể tham khảo tại: VPS 100% CPU? Nguyên nhân & hướng dẫn xử lý triệt để từ A-Z.
Liveness & Readiness Probes
Một ứng dụng có thể vẫn đang hoạt động (Process ID tồn tại), nhưng lại bị treo (Deadlock) ở tầng ứng dụng và không thể xử lý request. Các công cụ giám sát mức OS không thể biết điều này. Prometheus kết hợp với Kubernetes Probes sẽ cho bạn biết chính xác endpoint nào đang “ngừng hoạt động”.
Quản lý dung lượng lưu trữ (PVC)
Trong môi trường Container, dữ liệu thường được lưu trên các Persistent Volume Claim (PVC). Việc theo dõi dung lượng của từng volume gắn vào từng Pod là cực kỳ khó khăn nếu chỉ dùng lệnh df -h trên máy chủ vật lý. Prometheus cung cấp cái nhìn chi tiết về kubelet_volume_stats_available_bytes, giúp bạn biết chính xác Pod nào sắp hết chỗ lưu log hay data.
Thách thức đặc thù: Kiến trúc K3s và Chiến lược Giám sát
K3s được thiết kế tối giản bằng cách gộp các thành phần Control Plane (API Server, Controller Manager, Scheduler) vào một tiến trình duy nhất (Server Process). Điều này giúp K3s nhẹ hơn, nhưng lại gây khó khăn cho các công cụ giám sát được viết cho Kubernetes tiêu chuẩn.
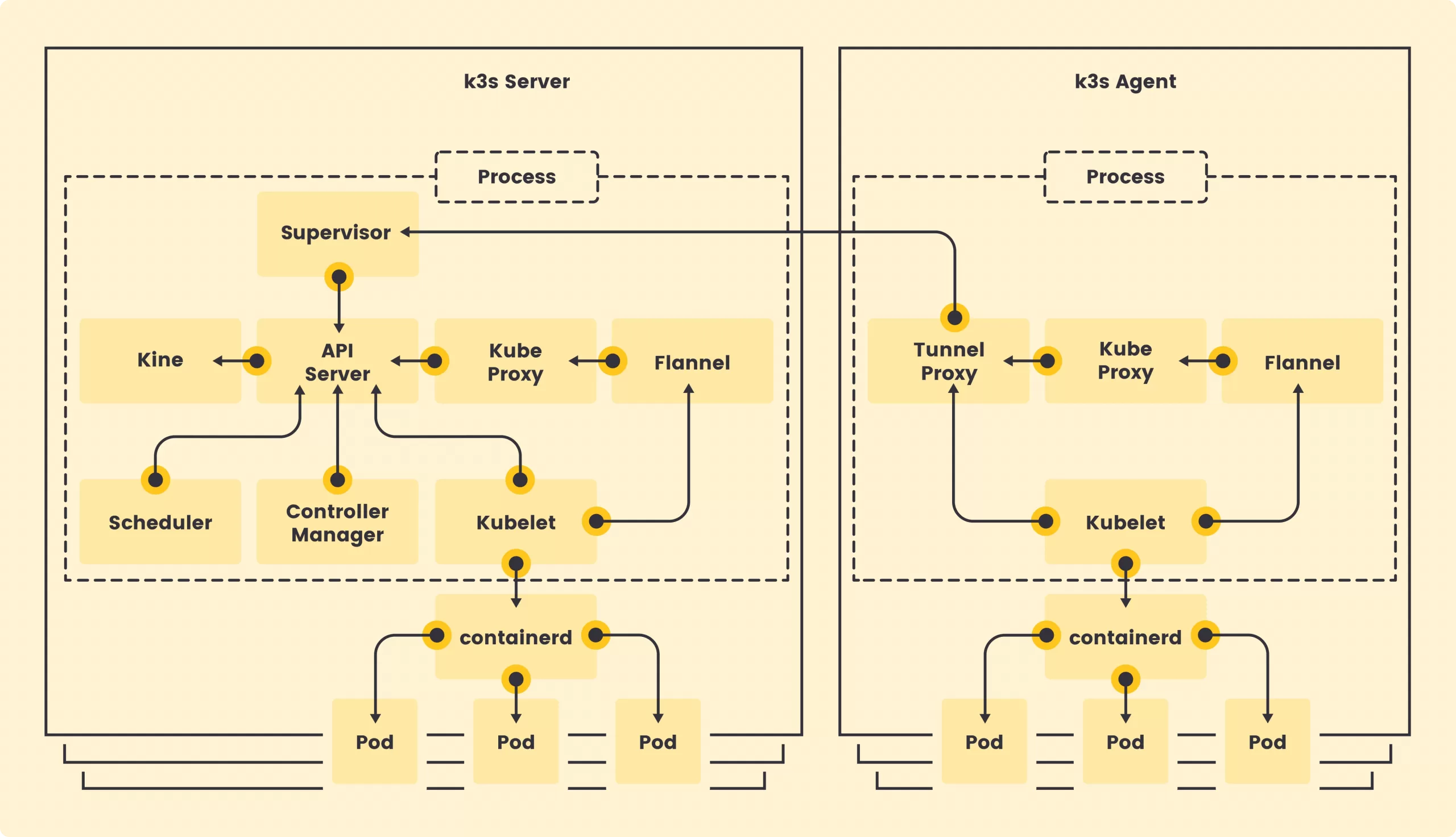
Sơ đồ kiến trúc K3s: Các thành phần Control Plane (API Server, Scheduler) được gói gọn trong một tiến trình Server duy nhất.
Prometheus mặc định sẽ cố gắng kết nối tới các cổng chuẩn (như 10257, 10259) để lấy dữ liệu. Trên K3s, các cổng này thường không được mở hoặc bind vào địa chỉ loopback (127.0.0.1) để bảo mật. Nếu cố tình cấu hình Prometheus để quét các mục tiêu này, bạn sẽ nhận về hàng loạt lỗi “Target Down” và làm rác logs.
Chiến lược tối ưu cho VPS: Chúng ta sẽ áp dụng chiến lược “Less is More”. Thay vì cố gắng giám sát các thành phần nội tại của K3s (vốn rất ổn định), chúng ta sẽ vô hiệu hóa việc giám sát Control Plane trong cấu hình Helm. Tài nguyên của Prometheus sẽ được tập trung 100% vào việc giám sát:
- Node Exporter: Sức khỏe phần cứng (Disk I/O, Network, CPU Host).
- Kubelet & cAdvisor: Sức khỏe của từng Container/Pod.
- Kube-State-Metrics: Trạng thái của các đối tượng K8s (Deployment, PVC, Ingress).
Bước 1: Chuẩn bị môi trường & cấu hình K3s chuẩn
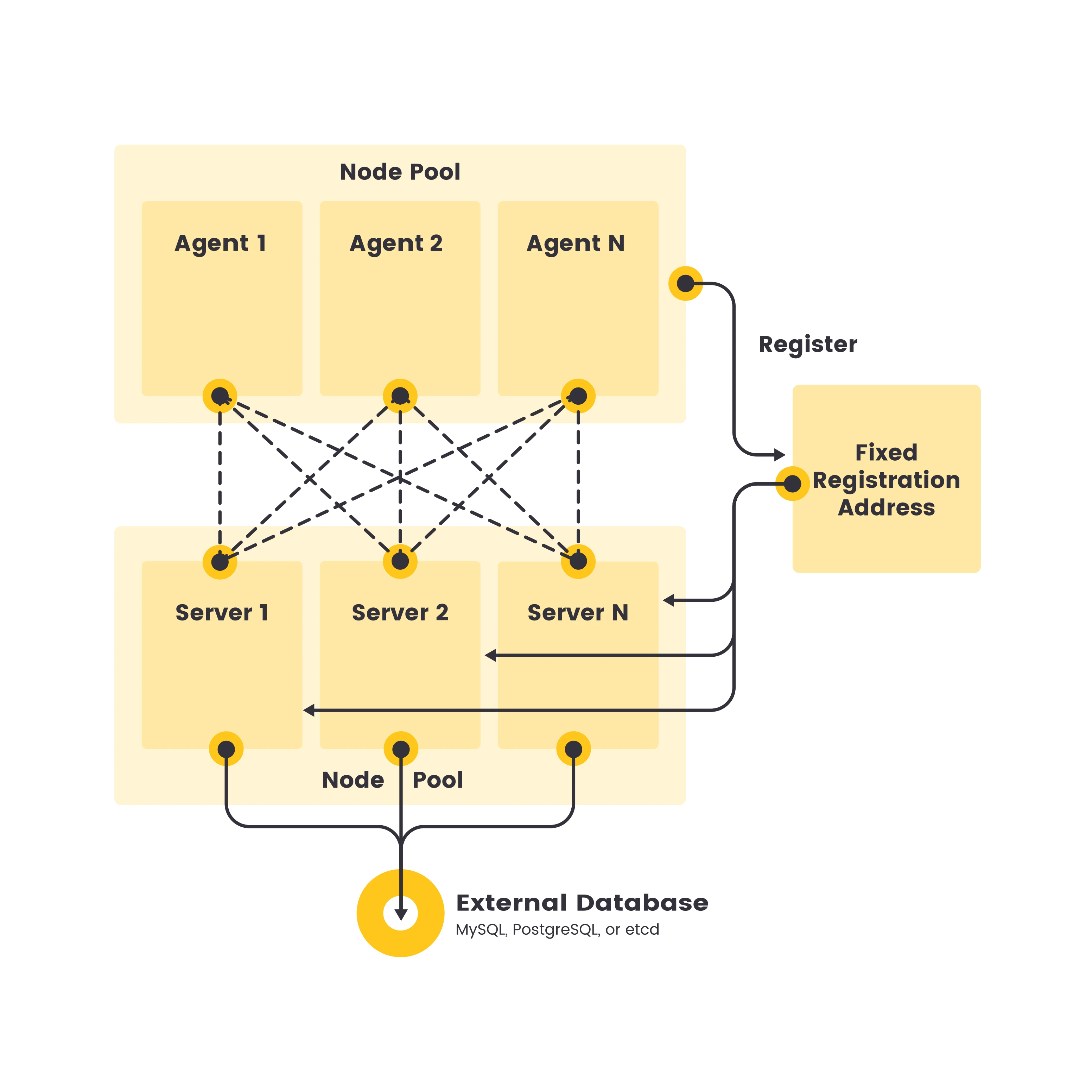
Mô hình triển khai K3s Cluster tiêu chuẩn cho môi trường Production với Node Pool và Database ngoài.
Yêu cầu phần cứng
Hệ thống giám sát Prometheus hoạt động dựa trên cơ sở dữ liệu chuỗi thời gian (Time-series Database), yêu cầu ghi đĩa liên tục và tiêu tốn nhiều RAM để cache các block dữ liệu mới nhất.
- CPU: Tối thiểu 2 vCPU.
- RAM: Tối thiểu 6GB RAM tổng cho VPS. (Monitoring Stack cần khoảng 2GB – 2.5GB RAM khả dụng).
- Disk: Sử dụng SSD hoặc NVMe. Tuyệt đối không dùng HDD vì độ trễ (Latency) sẽ làm Prometheus bị chậm khi truy vấn.
Cấu hình K3s bền vững
Một sai lầm phổ biến là sửa trực tiếp file service của systemd để cấu hình K3s. Điều này rất rủi ro vì khi bạn nâng cấp phiên bản K3s, file này có thể bị ghi đè. Phương pháp chuẩn là sử dụng file cấu hình YAML.
Nếu bạn chưa quen với các thao tác dòng lệnh, hãy xem qua Tổng hợp 20+ lệnh Linux cơ bản nhất cho người mới dùng VPS.
Tạo hoặc chỉnh sửa file cấu hình:
# /etc/rancher/k3s/config.yaml
write-kubeconfig-mode: "0644"
# Giữ nguyên các cấu hình mặc định khác để đảm bảo tính ổn địnhSau đó khởi động lại K3s:
sudo systemctl restart k3sTạo Namespace Monitoring
Việc cô lập tài nguyên là nguyên tắc vàng trong Kubernetes. Hãy tạo một không gian riêng cho Prometheus:
kubectl create namespace monitoringBước 2: Tối ưu values.yaml cho Kube-Prometheus-Stack
Cấu hình mặc định của Helm Chart kube-prometheus-stack được thiết kế cho các cluster Kubernetes tiêu chuẩn cỡ lớn. Nếu áp dụng nguyên xi vào K3s trên VPS, bạn sẽ gặp lỗi OOMKilled (tràn RAM) ngay lập tức. Việc cấu hình đúng ngay từ đầu cũng là một phần quan trọng trong chiến lược Bảo mật VPS Linux từ A-Z với 10 lớp phòng thủ thiết yếu.
Dưới đây là file cấu hình k3s-monitoring-values.yaml đã được tinh chỉnh, giải thích chi tiết từng tham số:
# k3s-monitoring-values.yaml
# --- PHẦN 1: TẮT CÁC THÀNH PHẦN KHÔNG TƯƠNG THÍCH ---
# K3s gộp Control Plane vào một binary, không lộ diện metrics qua các service chuẩn.
# Chúng ta tắt các job scrape này để Prometheus không báo lỗi và tiết kiệm tài nguyên.
kubeControllerManager:
enabled: false
kubeScheduler:
enabled: false
kubeEtcd:
enabled: false
kubeProxy:
enabled: false
# --- PHẦN 2: CẤU HÌNH PROMETHEUS SERVER ---
prometheus:
prometheusSpec:
# QUAN TRỌNG: Quản lý tài nguyên
# K3s yêu cầu bộ nhớ cao hơn mức mặc định của chart.
# Requests: Mức RAM đảm bảo dành riêng cho Prometheus.
# Limits: Mức trần. Nếu vượt quá 2500Mi, Pod sẽ bị restart để bảo vệ VPS.
resources:
requests:
memory: 1750Mi
cpu: 500m
limits:
memory: 2500Mi
cpu: 1000m
# Chính sách lưu trữ (Retention Policy)
# Retention by Time: Lưu log trong 10 ngày.
# Retention by Size: (Tùy chọn) Xóa bớt nếu log vượt quá 15GB.
retention: 10d
# Cấu hình ổ cứng (Persistent Volume)
storageSpec:
volumeClaimTemplate:
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi # Đảm bảo VPS còn đủ dung lượng đĩa thực
# storageClassName: local-path (K3s tự động dùng default)
# --- PHẦN 3: CẤU HÌNH GRAFANA ---
grafana:
# Bảo mật: Đặt mật khẩu admin ngay từ đầu
adminPassword: "ChangeMeStrongPassword123!"
# Lưu trữ Dashboard và User bền vững
persistence:
enabled: true
size: 5Gi
# Tắt Dashboard mặc định (thường nặng và không khớp với K3s)
defaultDashboardsEnabled: false
# --- PHẦN 4: ALERTMANAGER ---
alertmanager:
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5GiTại sao con số 2500Mi lại quan trọng? Theo các báo cáo thực tế từ cộng đồng Rancher và Sysdig, khi Prometheus khởi động lại (restart), nó cần tải lại các block dữ liệu từ đĩa lên RAM (WAL Replay). Quá trình này ngốn rất nhiều RAM đột biến. Nếu đặt limit quá thấp (ví dụ 1GB), Prometheus sẽ rơi vào vòng lặp vô tận: Khởi động -> Load WAL -> Hết RAM -> Crash -> Khởi động lại. Mức 2500Mi là mức an toàn cho các cluster nhỏ.
Bước 3: Triển khai Helm Chart
Sử dụng Helm giúp việc cài đặt, nâng cấp và gỡ bỏ trở nên đơn giản. Nếu bạn chưa biết về công cụ này, hãy tìm hiểu thêm tại bài viết Helm là gì? Cài đặt WordPress lên VPS Kubernetes chuẩn OCI.
Bước 1: Thêm Repo chính thức
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo updateBước 2: Cài đặt Stack
helm install monitoring-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
-f k3s-monitoring-values.yamlBước 3: Kiểm tra kết quả
kubectl get pods -n monitoring -wBạn cần chờ khoảng 2-5 phút để tất cả các image được tải về. Trạng thái thành công là tất cả Pod đều Running và Ready (1/1). Nếu Pod prometheus-monitoring-stack-prometheus-0 kẹt ở trạng thái Pending, hãy kiểm tra lại StorageClass của K3s bằng lệnh kubectl get sc. K3s thường cài sẵn local-path, nếu không thấy, bạn cần cài đặt provisioner này.
Nếu bạn cần giải pháp lưu trữ nâng cao hơn mặc định, hãy tham khảo Longhorn là gì? Triển khai Storage an toàn cho Kubernetes trên VPS (K3s).
Bước 4: Thiết lập Dashboard & Alerts thông minh
Truy cập Grafana
Để bảo mật, mặc định Grafana không lộ diện ra Public Internet. Chúng ta dùng Port-forwarding để truy cập cục bộ.
Bạn cần đảm bảo Firewall đã cho phép các kết nối cần thiết, xem thêm hướng dẫn Hướng dẫn mở port Firewall trên VPS Linux.
Chạy lệnh sau trên máy trạm của bạn:
kubectl port-forward -n monitoring svc/monitoring-stack-grafana 3000:80Sau đó truy cập trình duyệt tại địa chỉ: http://localhost:3000.
Dashboard chuyên dụng cho K3s
Dashboard mặc định của Kubernetes (ID 315, 6417…) thường hiển thị “N/A” ở nhiều ô do thiếu metrics Control Plane. Giải pháp tối ưu là sử dụng Dashboard ID 15282 (Kubernetes / K3s Cluster Monitoring).
Cách làm: Vào Grafana -> Dashboards -> Import -> Nhập ID 15282 -> Chọn Datasource Prometheus -> Import.
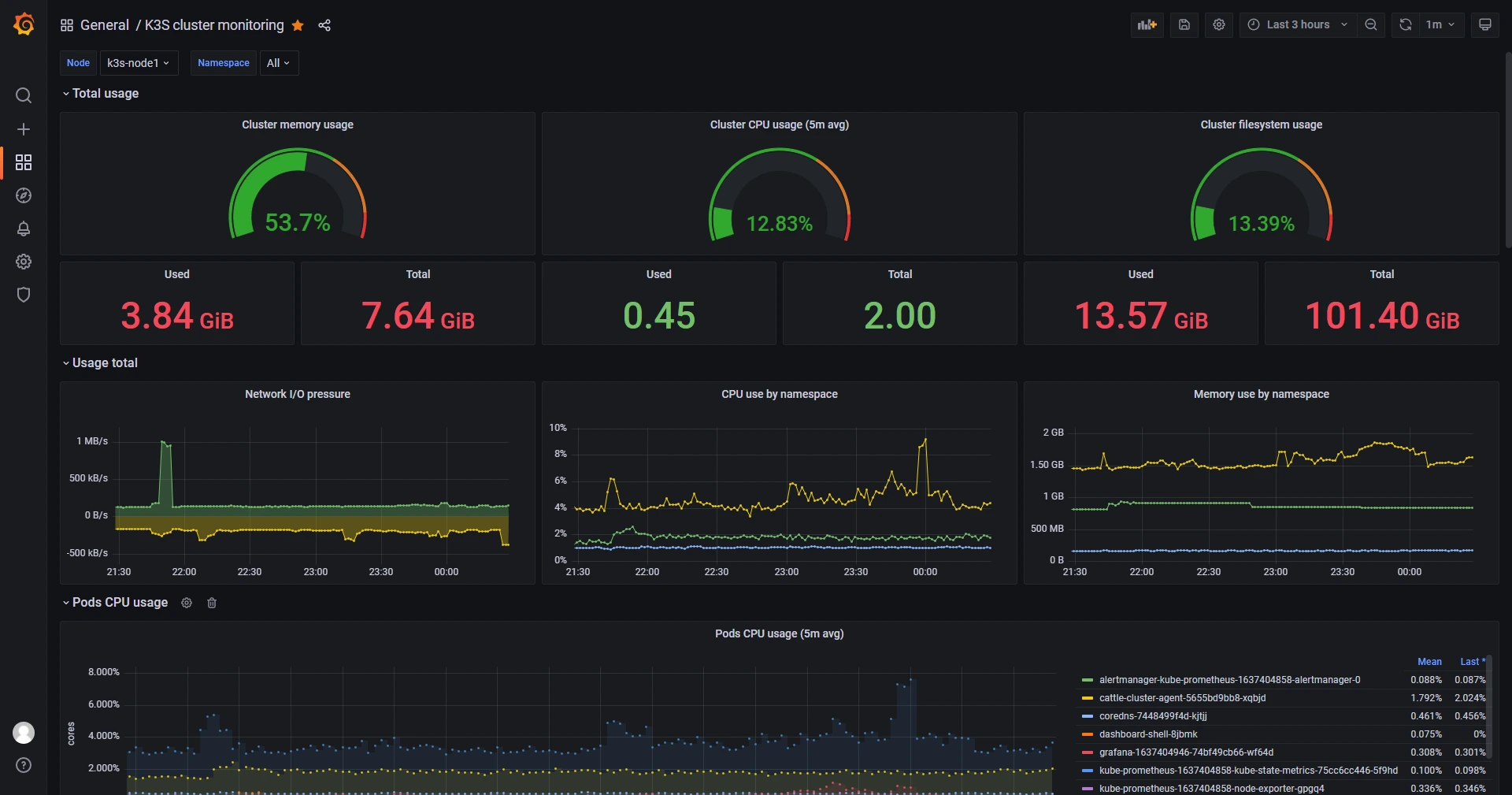
Giao diện Grafana Dashboard hiển thị tổng quan tài nguyên (CPU, RAM, Disk) của K3s Cluster sau khi cài đặt thành công.
Các thông số cần chú ý trên Dashboard này:
- Cluster CPU Usage: Nếu vượt quá 80% liên tục, bạn cần nâng cấp số core cho VPS.
- Pod Memory Usage: Đây là chỉ số quan trọng nhất. Hãy chú ý các đường biểu đồ đi lên dốc đứng (dấu hiệu Memory Leak).
- FS Usage (Filesystem): Cảnh báo khi ổ cứng đầy trên 85%. Ổ cứng đầy là nguyên nhân số 1 khiến Pod Database (MySQL, Postgres) bị lỗi.
Thiết lập AlertManager qua Kubernetes Secret
Để nhận cảnh báo về điện thoại (Telegram/Slack), bạn cần cấu hình AlertManager. Thay vì sửa ConfigMap thủ công, hãy tạo một Secret chuẩn.
Nếu bạn cần cấu hình phức tạp hơn, có thể đọc thêm bài Hướng dẫn cấu hình Alertmanager cho Prometheus.
Ví dụ cấu hình gửi cảnh báo Critical qua Telegram. Tạo file alertmanager-secret.yaml:
apiVersion: v1
kind: Secret
metadata:
name: alertmanager-monitoring-stack-alertmanager
namespace: monitoring
type: Opaque
stringData:
alertmanager.yaml: |
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'telegram-receiver'
routes:
- match:
severity: critical
receiver: 'telegram-receiver'
receivers:
- name: 'telegram-receiver'
telegram_configs:
- bot_token: '123456789:AAHExxxxxxxxx' # Thay bằng Token của bạn
chat_id: -987654321 # Thay bằng Chat ID GroupÁp dụng cấu hình:
kubectl apply -f alertmanager-secret.yamlCác chỉ số PromQL “bắt bệnh” hệ thống
Để thực sự làm chủ việc giám sát Kubernetes, bạn cần biết cách truy vấn dữ liệu thô để tìm nguyên nhân gốc rễ (Root Cause Analysis).
Tìm Pod tiêu thụ nhiều CPU nhất:
topk(10, rate(container_cpu_usage_seconds_total[5m]))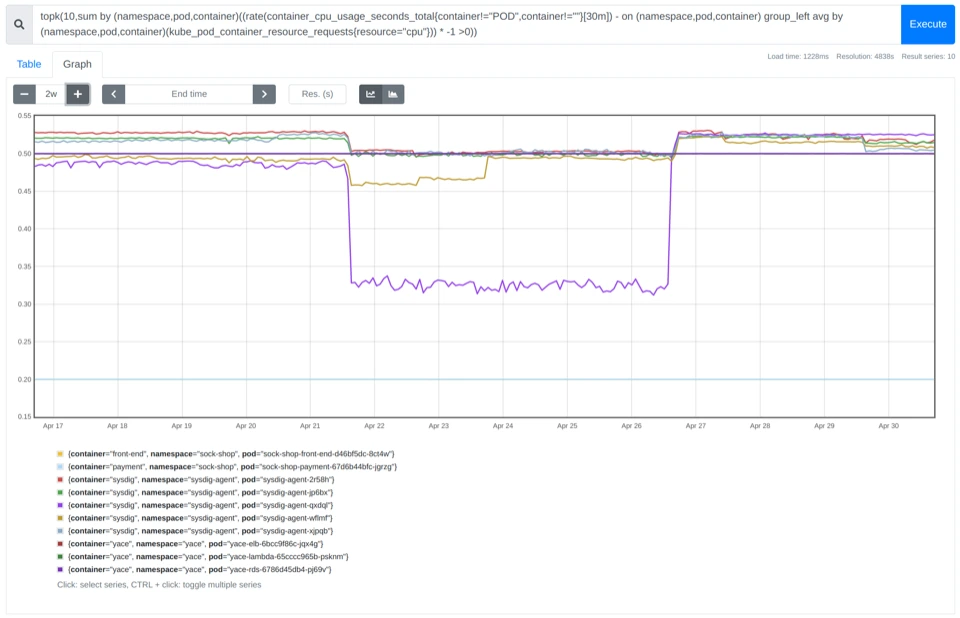
Biểu đồ theo dõi Top 10 Pod tiêu thụ nhiều CPU nhất giúp phát hiện nhanh các ứng dụng đang gây quá tải hệ thống.
Tìm Pod bị CrashLoopBackOff:
rate(kube_pod_container_status_restarts_total[15m]) > 0Nếu chỉ số này > 0, tức là có Pod đang ngừng hoạt động và khởi động lại liên tục.
Kiểm tra sự lãng phí tài nguyên (Rightsizing):
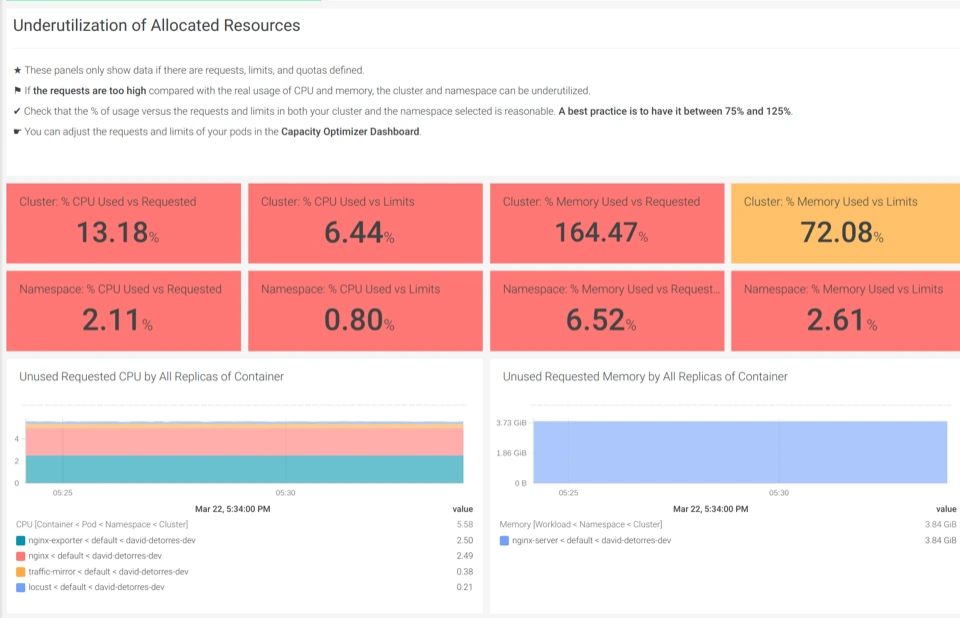
Bảng theo dõi mức độ lãng phí tài nguyên (Underutilization) và các Namespace vượt quá giới hạn để tối ưu chi phí hạ tầng.
Kiểm tra xem Pod nào đang yêu cầu (Request) quá nhiều CPU so với thực tế sử dụng:
sum(kube_pod_container_resource_requests{resource="cpu"}) by (pod) - sum(rate(container_cpu_usage_seconds_total[5m])) by (pod)Mở rộng: Giám sát ứng dụng riêng với ServiceMonitor
Đây là phần nâng cao giúp hệ thống giám sát Kubernetes của bạn trở nên hoàn hảo. Prometheus Operator sử dụng một Custom Resource Definition (CRD) gọi là ServiceMonitor để tự động phát hiện các ứng dụng cần giám sát.
Giả sử bạn có một Deployment Nginx và muốn giám sát lượng request vào nó.
Bước 1: Expose Metrics từ ứng dụng
Ứng dụng phải có một đường dẫn /metrics (ví dụ sử dụng nginx-prometheus-exporter).
Bước 2: Gán label cho Service
Service của Nginx phải có label để Prometheus nhận diện.
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
app: my-nginx
release: monitoring-stack # Quan trọng: Phải khớp với release name của Prometheus
spec:
ports:
- name: web
port: 80
- name: metrics
port: 9113
selector:
app: my-nginxBước 3: Tạo ServiceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: my-nginx-monitor
namespace: monitoring
labels:
release: monitoring-stack
spec:
selector:
matchLabels:
app: my-nginx # Chọn Service có label này
endpoints:
- port: metrics
interval: 15sNgay sau khi apply file này, Prometheus sẽ tự động thêm Nginx vào danh sách Targets mà không cần bạn phải khởi động lại server hay sửa file config.
Phân tích sự cố (Troubleshooting) & bảo trì
Hệ thống giám sát cũng cần được… giám sát. Dưới đây là các kịch bản thực tế bạn sẽ gặp sau 3-6 tháng vận hành.
Sự cố 1: Prometheus bị CrashLoopBackOff do trôi nổi dữ liệu (WAL Corruption)
Nếu VPS bị tắt đột ngột (mất điện), file Write-Ahead Log (WAL) của Prometheus có thể bị lỗi.
Khắc phục: Bạn buộc phải xóa các file WAL bị lỗi trong thư mục data của Pod Prometheus. Đôi khi cách nhanh nhất là xóa Pod để nó mount lại volume (nếu lỗi nhẹ) hoặc xóa luôn PVC (chấp nhận mất dữ liệu cũ) để khởi tạo lại từ đầu.
Sự cố 2: Đĩa cứng bị đầy (Disk Pressure)
Prometheus ghi dữ liệu rất “hung hãn”. Nếu bạn thấy disk đầy, đừng chỉ tăng dung lượng đĩa.
Khắc phục:
- Giảm
retentiontrongvalues.yamlxuống còn 5 ngày hoặc 7 ngày. - Kiểm tra xem có metric nào đang spam dữ liệu không (High Cardinality). Ví dụ: một metric ghi lại ID của từng request HTTP sẽ làm phình to database cực nhanh. Hãy dùng các câu lệnh PromQL để tìm và loại bỏ (drop) các metrics này.
Nâng cấp Helm Chart
Thường xuyên cập nhật Monitoring Stack là tốt, nhưng hãy cẩn thận với CRD (Custom Resource Definitions). Helm thường không tự động update CRD. Quy trình chuẩn:
- Đọc Release Notes của
kube-prometheus-stack. - Cập nhật CRD thủ công bằng
kubectl apply. - Chạy
helm upgrade.
Câu hỏi thường gặp (FAQ)
1. K3s khác gì Kubernetes thường trong việc giám sát?
Khác biệt lớn nhất là Kiến trúc. Kubernetes thường chạy các thành phần quản lý (Controller, Scheduler) trên các Pod riêng biệt và mở cổng để giám sát. Ngược lại, K3s gói tất cả vào một tiến trình duy nhất (Single Binary) để nhẹ hơn. Hệ quả: Prometheus mặc định không thể kết nối tới các cổng chuẩn của K8s. Bạn buộc phải tắt (disable) việc giám sát Control Plane và tập trung vào giám sát Node/Pod ứng dụng.
2. VPS 2GB RAM có chạy được bộ Monitoring này không?
Không nên. Dù K3s nhẹ, nhưng Prometheus + Grafana cần cache dữ liệu trên RAM. Tổng hệ thống cần khoảng 2.5GB RAM để hoạt động ổn định. Chạy trên VPS 2GB sẽ gây tràn bộ nhớ (Swap), làm treo cả ứng dụng chính. Hãy nâng cấp lên VPS cấu hình cao (tối thiểu 4GB RAM).
3. Tại sao tôi không thấy metrics của Controller Manager và Scheduler trên Grafana?
Vì chúng ta đã chủ động tắt nó. Do đặc thù K3s (xem câu 1), các metrics này thường bị ẩn hoặc bind vào localhost. Việc cố gắng bật chúng thường gây lỗi “Target Down” và rác log. Với người dùng VPS, các chỉ số này không quan trọng bằng CPU/RAM của Node và Pod.
4. Dữ liệu giám sát chiếm bao nhiêu dung lượng ổ cứng?
Khoảng 5GB – 10GB. Với cấu hình lưu trữ 10 ngày cho một cluster nhỏ (~20 Pods). Prometheus ghi dữ liệu liên tục, nên cần dùng ổ SSD/NVMe. Nếu ổ cứng đầy, hãy giảm retention xuống 5 ngày hoặc xem hướng dẫn 7 lệnh Linux xử lý nhanh lỗi VPS bị đầy ổ cứng.
5. Làm thế nào để đổi mật khẩu admin Grafana chuẩn nhất?
Đổi trong values.yaml, KHÔNG đổi trên giao diện web. Mật khẩu trên giao diện sẽ bị mất khi Pod khởi động lại. Cách làm: Sửa dòng adminPassword trong file k3s-monitoring-values.yaml và chạy lệnh helm upgrade ....
6. Tôi có thể nhận cảnh báo qua Zalo không?
Chưa hỗ trợ sẵn (Native). AlertManager hỗ trợ tốt nhất cho Email, Slack, Telegram. Để dùng Zalo, bạn cần tự viết code trung gian (Webhook). Khuyên dùng Telegram vì thiết lập nhanh (5 phút), miễn phí và độ ổn định cao.
Kết luận
Triển khai hệ thống giám sát Kubernetes trên K3s là một bước tiến lớn trong việc chuyên nghiệp hóa quy trình vận hành (DevOps). Nó chuyển đổi trạng thái làm việc của bạn từ “phản ứng sự cố” (Reactive) sang “chủ động ngăn chặn” (Proactive).
Bằng việc cấu hình tài nguyên RAM hợp lý (2500Mi), sử dụng config.yaml cho K3s và tận dụng sức mạnh của ServiceMonitor, bạn đã xây dựng được một đài quan sát kiên cố ngay trên nền tảng VPS tiết kiệm chi phí.
Hệ thống giám sát Prometheus là một tác vụ I/O intensive (ghi đọc ổ cứng cường độ cao). Nếu bạn đang gặp tình trạng biểu đồ Grafana bị đứt đoạn hoặc load chậm, đó là dấu hiệu VPS hiện tại đang bị nghẽn IOPS. Hãy tham khảo ngay các gói Cloud VPS NVMe Enterprise của chúng tôi – hạ tầng tối ưu cho Kubernetes và Database, đảm bảo dữ liệu giám sát luôn mượt mà và tin cậy.
Tài liệu tham khảo