Cách giám sát VPS với OpenTelemetry và Grafana toàn diện (2026)
2 giờ sáng, tiếng chuông PagerDuty réo rắt báo hiệu production đang có biến. Bạn bật dậy, SSH vào VPS và đối mặt với cảnh tượng kinh hoàng: CPU spike lên 100%, API bị rate-limit liên tục do quá tải request, RAM thì đang cạn kiệt. Theo phản xạ, bạn mở tab Grafana để xem metrics hệ thống, lật đật mở Kibana để mò mẫm file log Nginx, rồi lại chuyển sang một tool khác để check trace xem đoạn code nào đang thắt cổ chai. Việc phải nhảy qua nhảy lại giữa hàng tá công cụ rời rạc khiến quá trình debug chẳng khác nào mò kim đáy bể, trong khi downtime đang đốt tiền của công ty từng giây.
Đó là nỗi đau chung của rất nhiều sysadmin và DevOps engineer khi vẫn đang duy trì những stack giám sát chắp vá. Nhưng chúng ta đang ở năm 2026, thời điểm mà khái niệm Observability (Quan sát hệ thống) đã chuyển mình mạnh mẽ. Thay vì cài đặt hàng tá agent cồng kềnh, bạn chỉ cần duy nhất một đầu mối thu thập mọi tín hiệu. Giải pháp hợp nhất và tối ưu nhất hiện nay chính là giám sát VPS với OpenTelemetry.
Bạn đã sẵn sàng vứt bỏ mớ công cụ cũ kỹ, nặng nề để nâng cấp hạ tầng của mình lên tiêu chuẩn de facto của năm 2026 chưa? Cách quy hoạch lại toàn bộ dữ liệu viễn trắc (telemetry) trên máy chủ ra sao để vừa nhẹ, vừa mượt, lại bắt đúng bệnh của hệ thống? Cùng tôi bóc tách chi tiết kiến trúc và cách triển khai thực chiến ngay dưới đây nhé!
Bài viết liên quan: Đừng bỏ lỡ bài viết Tầm quan trọng của giám sát VPS & các công cụ phổ biến nếu bạn là người mới bắt đầu làm quen với hệ thống.
Tại sao stack giám sát VPS cũ lại trở thành bom nổ chậm?

Sự khác biệt giữa mô hình giám sát truyền thống (gây nghẽn cổ chai, silo dữ liệu) và mô hình hợp nhất bằng OpenTelemetry.
Nếu bạn vẫn đang gánh một hệ thống với combo Prometheus (Node Exporter) + ELK/EFK (Fluentd/Promtail) + Jaeger/Zipkin Agent, bạn đang tự tạo ra những rào cản lớn cho chính hạ tầng của mình. Ở quy mô scale lớn hoặc khi cần tối ưu tài nguyên cho các cụm server, kiến trúc này bộc lộ những điểm yếu chí mạng:
- Gây lãng phí tài nguyên hệ thống (Resource Waste): Để có đủ bộ 3 trụ cột của Observability (Metrics, Logs, và Traces), bạn phải cài đặt và duy trì ít nhất 3 agent khác nhau trên cùng một VPS. Mỗi agent đều phải thực hiện các tác vụ tương tự nhau như thu thập dữ liệu, tuần tự hóa (serialization) và truyền tải qua mạng. Sự lặp lại này làm tăng đáng kể chi phí hiệu năng (overhead). Với những con VPS cấu hình thấp, việc gánh các agent này đôi khi lại chính là nguyên nhân gây nghẽn cổ chai.
- Tạo ra silo dữ liệu (Data Silos) và cản trở việc phân tích: Vấn đề cốt lõi của mô hình cũ là các agent không chia sẻ các định danh chung (như Trace ID) hay các nhãn đồng nhất. Metric từ Node Exporter báo CPU cao, nhưng nó không cho bạn biết chính xác dòng log nào hay trace nào của ứng dụng gây ra việc đó. Việc phải tự xâu chuỗi dữ liệu thủ công từ các silo này làm chậm quá trình gỡ lỗi (Root Cause Analysis).
- Vendor Lock-in: Bạn bị trói buộc vào định dạng dữ liệu của từng nhà cung cấp. Giả sử ngày mai tổ chức muốn chuyển backend lưu trữ từ Prometheus sang Datadog, New Relic hay Dynatrace, bạn gần như phải xây dựng lại toàn bộ phần cấu hình thu thập dữ liệu trên các máy chủ.
OpenTelemetry (OTel) ra đời dưới sự bảo trợ của CNCF (Cloud Native Computing Foundation) để giải quyết triệt để bài toán này với một triết lý duy nhất: Một Agent hợp nhất, một chuẩn dữ liệu OTLP duy nhất.
Kiến trúc hợp nhất 2026: OTel Collector, Grafana Alloy và LGTM Stack
Để hiểu rõ cách hệ thống vận hành, hãy nhìn vào kiến trúc chuẩn của một pipeline giám sát hiện đại.
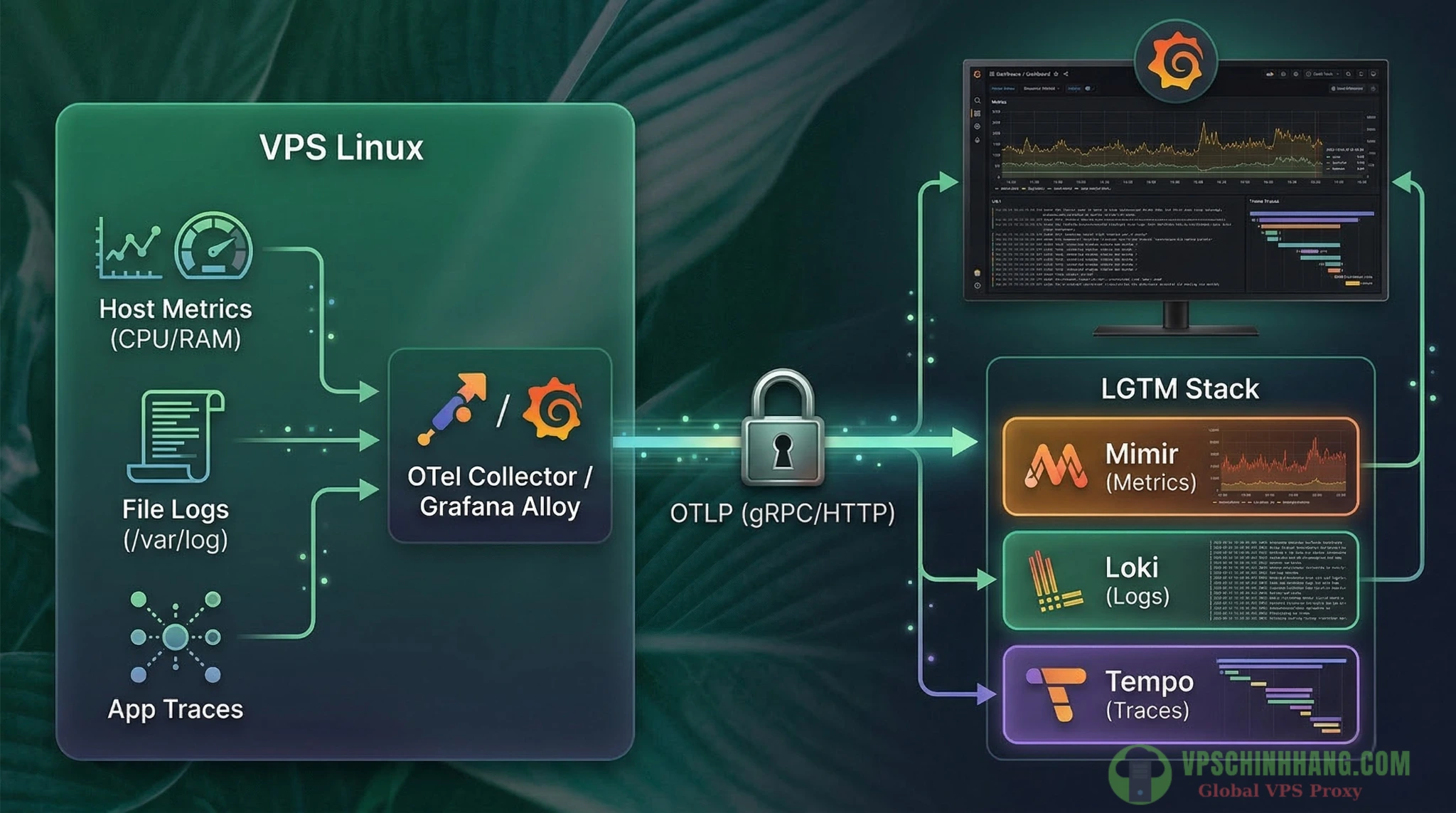
Kiến trúc thu thập và xử lý dữ liệu viễn trắc (Telemetry) hiện đại: 1 Agent – 1 Chuẩn OTLP – 1 Giao diện Grafana duy nhất.
Trái tim hệ thống: Sự chuyển giao giữa OTel Collector và Grafana Alloy
Thành phần cốt lõi nằm trên VPS của bạn là một Agent thu thập dữ liệu. Hiện nay, bạn có hai lựa chọn tối ưu nhất:
- OpenTelemetry Collector (Bản Contrib): Là phiên bản mở rộng của OTel, chứa đầy đủ các module cần thiết để đọc thông số VPS (
hostmetrics) và đọc file log (filelog). Nó hoạt động theo mô hình luồng dữ liệu tuyến tính (linear pipeline) với cấu hình YAML tiêu chuẩn. OTel Collector hoàn toàn trung lập (vendor-neutral), mang lại sự linh hoạt tối đa. - Grafana Alloy: Nếu toàn bộ backend của bạn sử dụng hệ sinh thái Grafana, hãy chú ý đến cái tên này. Theo thông báo từ Grafana Labs, Grafana Agent cũ đã chính thức bước vào giai đoạn LTS và bị khai tử để dọn đường cho Grafana Alloy. Alloy sử dụng cấu trúc đồ thị có hướng không chu trình (DAG) với cú pháp
.alloy, cho phép định tuyến luồng dữ liệu cực kỳ linh hoạt (hỗ trợ biến, logic điều kiện). Nó được tích hợp sẵn (native) các pipeline hoàn hảo để scrape dữ liệu Prometheus và Continuous Profiling thông qua Pyroscope.
Backend lưu trữ: Sức mạnh của LGTM Stack
Khi dữ liệu đã được thu thập và chuẩn hóa thành định dạng OTLP, nó sẽ được đẩy về một hệ thống lưu trữ tập trung. Bộ tứ LGTM (Loki, Grafana, Tempo, Mimir) đang làm mưa làm gió nhờ khả năng tương quan chéo tín hiệu (cross-signal correlation):
- Grafana Loki (Logs): Khi nhận dữ liệu log OTLP, Loki sẽ tự động chuyển đổi các thuộc tính tài nguyên (như
service.name) thành các nhãn (labels), giúp việc lưu trữ và truy vấn siêu nhẹ, siêu rẻ. - Grafana Tempo (Traces): Backend lưu trữ dấu vết phân tán ở quy mô lớn. Tempo có tính năng
metrics_generatorcực hay, tự động phân tích traces đầu vào để tạo ra các chỉ số RED (Rate, Errors, Duration) và đẩy thẳng sang Mimir. - Grafana Mimir (Metrics): Backend lưu trữ metrics hiệu năng cao, thay thế hoàn hảo cho Prometheus ở quy mô doanh nghiệp. Nó quản lý các exemplars (mẫu dữ liệu đính kèm Trace ID vào metric) để phục vụ đối chiếu.
- Grafana (Visualization): Đóng vai trò là giao diện truy vấn hợp nhất. Sức mạnh cốt lõi là cho phép bạn nhấp vào một biểu đồ metric bị lỗi, nhảy trực tiếp đến trace gây ra lỗi, rồi từ trace nhảy đến dòng log chi tiết.
Có thể bạn quan tâm: Tìm hiểu chi tiết về sự khác biệt giữa các hệ thống qua bài So sánh Prometheus và Grafana.
Thực chiến: Triển khai giám sát VPS với OpenTelemetry
Lý thuyết như vậy là đủ. Bây giờ, chúng ta sẽ bắt tay vào gõ lệnh để cấu hình hệ thống giám sát trên một con Linux VPS (Ubuntu/Debian) cấu trúc amd64.
Bước 1: Cài đặt OTel Collector Contrib (cập nhật bản v0.147.0)
Để thu thập đầy đủ host metrics và file logs trên VPS, chúng ta bắt buộc phải dùng phiên bản Contrib (vì bản Core không chứa các receiver mở rộng). Tính đến đầu năm 2026, phiên bản ổn định và giải quyết được nhiều vấn đề cũ nhất là v0.147.0.
Hãy chạy chuỗi lệnh sau:
Cập nhật hệ thống và cài đặt wget:
sudo apt-get update && sudo apt-get install -y wgetTải OTel Collector Contrib phiên bản v0.147.0 mới nhất:
wget https://github.com/open-telemetry/opentelemetry-collector-releases/releases/download/v0.147.0/otelcol-contrib_0.147.0_linux_amd64.debCài đặt package:
sudo dpkg -i otelcol-contrib_0.147.0_linux_amd64.debKích hoạt và khởi động service:
sudo systemctl enable otelcol-contrib
sudo systemctl start otelcol-contribKiểm tra trạng thái:
systemctl status otelcol-contribBước 2: Cấu hình Receivers (Host Metrics & Filelog)
File cấu hình chính nằm tại /etc/otelcol-contrib/config.yaml. Dưới đây là cấu hình chuẩn chỉ để biến OTel Collector thành một cỗ máy giám sát VPS toàn diện, kết hợp các bộ lọc (filter) để loại bỏ dữ liệu thừa:
receivers:
# 1. Thu thập Host Metrics (Thay thế hoàn toàn Node Exporter)
hostmetrics:
collection_interval: 30s
scrapers:
cpu: {}
memory: {}
disk: {}
load: {}
filesystem:
exclude_fs_types:
fs_types: [tmpfs, devfs, devtmpfs, proc, sysfs, overlay]
match_type: strict
network:
exclude:
interfaces: [lo, loopback, "docker.*", "veth.*"]
match_type: regexp
# 2. Thu thập Logs hệ thống và ứng dụng
filelog:
include:
- /var/log/syslog
- /var/log/nginx/access.log
start_at: end
# 3. Nhận Traces/Metrics trực tiếp từ App qua OTLP
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
# Giới hạn RAM cho Collector, tránh OOM (Out of Memory) crash VPS
memory_limiter:
check_interval: 1s
limit_mib: 256
spike_limit_mib: 64
resourcedetection:
detectors: [system]
system:
hostname_sources: [os]
batch:
timeout: 5s
send_batch_size: 1024
exporters:
# Đẩy metrics về Grafana Mimir
prometheusremotewrite:
endpoint: "http://your-mimir-server:9009/api/v1/push"
# Đẩy logs về Grafana Loki
loki:
endpoint: "http://your-loki-server:3100/loki/api/v1/push"
# Đẩy traces về Grafana Tempo
otlp/tempo:
endpoint: "http://your-tempo-server:4317"
tls:
insecure: true
service:
pipelines:
metrics:
receivers: [hostmetrics, otlp]
processors: [memory_limiter, resourcedetection, batch]
exporters: [prometheusremotewrite]
logs:
receivers: [filelog, otlp]
processors: [memory_limiter, resourcedetection, batch]
exporters: [loki]
traces:
receivers: [otlp]
processors: [memory_limiter, resourcedetection, batch]
exporters: [otlp/tempo]
Lưu ý thực chiến cực kỳ quan trọng về Filelog (Bản v0.147.0):
Nếu bạn từng cấu hình OTel Collector các bản cũ, hẳn bạn đã gặp khó khăn khi service bị kẹt ở trạng thái Not Ready hàng chục phút lúc khởi động, hoặc liên tục spam log cảnh báo no files match the configured criteria.
Lý do là module
pkg/fileconsumercũ thực hiện một quá trình rà soát file đồng bộ (synchronous glob walk) toàn bộ ổ đĩa lúc startup. Tuy nhiên, từ phiên bản v0.147.0, cơ chế rà soát file đồng bộ nghiêm trọng này đã bị loại bỏ hoàn toàn. Giờ đây, Collector khởi động chớp nhoáng, không bị block kể cả khi thư mục log của bạn chứa hàng vạn file. Việc nâng cấp lên v0.147.0 là mệnh lệnh bắt buộc để đảm bảo uptime!
Bảo mật: Đừng bao giờ chạy OTel Collector dưới quyền root. Hãy tham khảo Bảo mật VPS Linux từ A-Z với 10 lớp phòng thủ thiết yếu (cập nhật 2025) để tạo một user riêng (otelcol), cấp cho nó quyền đọc log (usermod -aG adm otelcol) và cấp capability mạng nếu cần (setcap cap_net_admin+ep /usr/bin/otelcol-contrib).
Bước 3: Đừng vội đập bỏ Prometheus (mẹo từ chuyên gia)
Khi ứng dụng web/API của bạn đang hoạt động ổn định với thư viện Prometheus native, đừng vì trào lưu OpenTelemetry mà ép team Dev phải viết lại (instrument) toàn bộ code sang chuẩn OTel SDK.
Theo chính Julius Volz (Co-founder của Prometheus) tại PromLabs, việc giữ lại Prometheus native cho Metrics mang lại 6 lợi thế không thể chối cãi:
- Target health monitoring: Prometheus dùng cơ chế pull, dễ dàng phát hiện target ngừng hoạt động qua metric
up. OTLP dùng cơ chế push, rất khó phân biệt app bị tắt chủ ý hay bị crash. - SDK siêu nhẹ và nhanh: Native Prometheus SDK trên Go xử lý nhanh hơn từ 4.4 đến 26 lần và không ngốn thêm bộ nhớ cấp phát (zero allocations) so với OTel SDK cồng kềnh.
- Tránh nhiễu loạn tên metric: OTel tự động biến đổi tên (thêm hậu tố, đổi dấu chấm thành gạch dưới) làm vỡ nát các câu PromQL.
- Không cần Join phức tạp: OTel đẩy metadata thành một metric
target_inforiêng, khiến bạn phải dùng hàmjoincực kỳ đau đầu để truy vấn. - Tiêu chuẩn mở tối giản: Định dạng text của Prometheus dễ đến mức có thể viết bằng vài dòng shell script, thay vì cấu trúc protocol-buffer phức tạp.
Giải pháp: Hãy giữ nguyên các endpoint /metrics cũ của ứng dụng. Sau đó, cấu hình một prometheus receiver ngay trong file config.yaml của OTel Collector để nó đóng vai trò như một máy chủ đi thu thập (scrape) dữ liệu:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'my-legacy-app'
scrape_interval: 15s
static_configs:
- targets: ['localhost:8080']
Vừa khỏe cho Dev, vừa nhàn cho Sysadmin!
Gỡ rối PromQL với Semantic Conventions (phiên bản v1.40.0)
Khi giám sát VPS với OpenTelemetry bằng hostmetrics, cú sốc lớn nhất là các Dashboard cũ của bạn sẽ đồng loạt báo No Data. Nguyên nhân là do OTel áp dụng Semantic Conventions (Quy ước ngữ nghĩa) để thống nhất mọi định danh.
Tính đến năm 2026, hệ thống sử dụng Semantic Conventions v1.40.0. Bản cập nhật này đã cấu trúc lại toàn bộ các Attribute Keys (khóa thuộc tính) bằng cách gắn thêm prefix cực kỳ chặt chẽ. Dưới đây là bảng ánh xạ (mapping) chuẩn xác nhất để bạn sửa lại PromQL:
| Thông số | Prometheus (Node Exporter cũ) | OTel Semantic Conventions (v1.40.0) | Giải thích sự thay đổi |
| CPU Time | node_cpu_seconds_total |
system.cpu.time |
Gom chung thành 1 metric, lọc trạng thái qua thuộc tính cpu.mode (user, system, idle…). |
| Memory | node_memory_MemFree_bytes |
system.memory.usage{system.memory.state="free"} |
CỰC KỲ LƯU Ý: Khóa thuộc tính đã đổi từ state thành system.memory.state. |
| Disk I/O | node_disk_read_bytes_total |
system.disk.io{disk.io.direction="read"} |
Hướng I/O đổi từ direction thành disk.io.direction. |
| Filesystem | node_filesystem_avail_bytes |
system.filesystem.usage{system.filesystem.state="free"} |
Trạng thái ổ đĩa đổi thành system.filesystem.state. |
| Network | node_network_receive_bytes_total |
system.network.io{network.io.direction="receive"} |
Hướng truyền tải đổi thành network.io.direction. |
Mẹo cứu cánh cho Dashboard cũ: Nếu bạn có hàng trăm bảng theo dõi và chưa kịp sửa PromQL, hãy cấu hình resource_to_telemetry_conversion: enabled: true trong exporter prometheusremotewrite của OTel Collector. Tính năng này sẽ tự động thăng cấp (promote) các Resource Attributes của OTel thành các nhãn (labels) gắn trực tiếp vào chuỗi thời gian, giúp dashboard cũ hoạt động bình thường mà không cần sửa code.
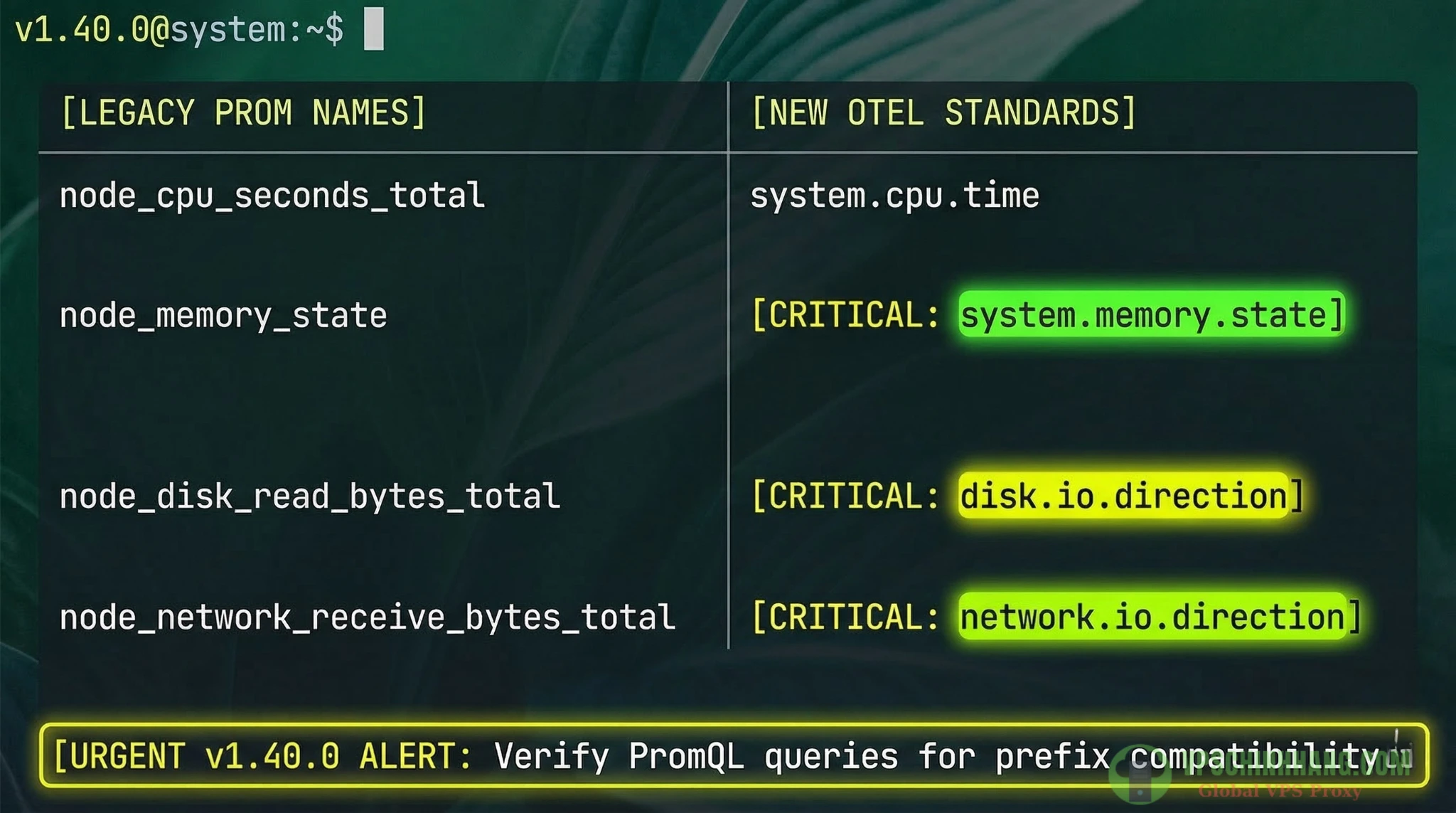
Cập nhật PromQL chuẩn xác theo tài liệu OpenTelemetry Semantic Conventions v1.40.0 (Chú ý các tiền tố thuộc tính mới).
Killer Feature: Cấu hình Derived Fields để liên kết logs và traces
Đây chính là đỉnh cao của Observability, biến hệ thống giám sát của bạn từ mức đọc dữ liệu sang mức thấu hiểu luồng dữ liệu.
Bạn mở Grafana Loki và thấy một dòng báo lỗi 500 Internal Server Error. Thay vì copy mốc thời gian qua Tempo tìm kiếm, bạn có thể biến chuỗi trace_id trong log thành một đường link click trực tiếp.
Vào Connections > Data sources trên Grafana, chọn Data Source Loki, cuộn xuống mục Derived Fields và thiết lập:
- Name:
TraceID(Tên nhãn sẽ hiển thị) - Type:
Regex - Regex:
'"trace_id":"(\w+)"'(Đoạn regex này bắt chính xác chuỗi hex 32 ký tự của trace_id chuẩn hóa OTLP trong log JSON. Nếu log của bạn dạng text logfmt, dùngtrace_id=(\w+)) - Query / URL:
${__value.raw} - Internal Link: Bật On và trỏ về Data Source Tempo.
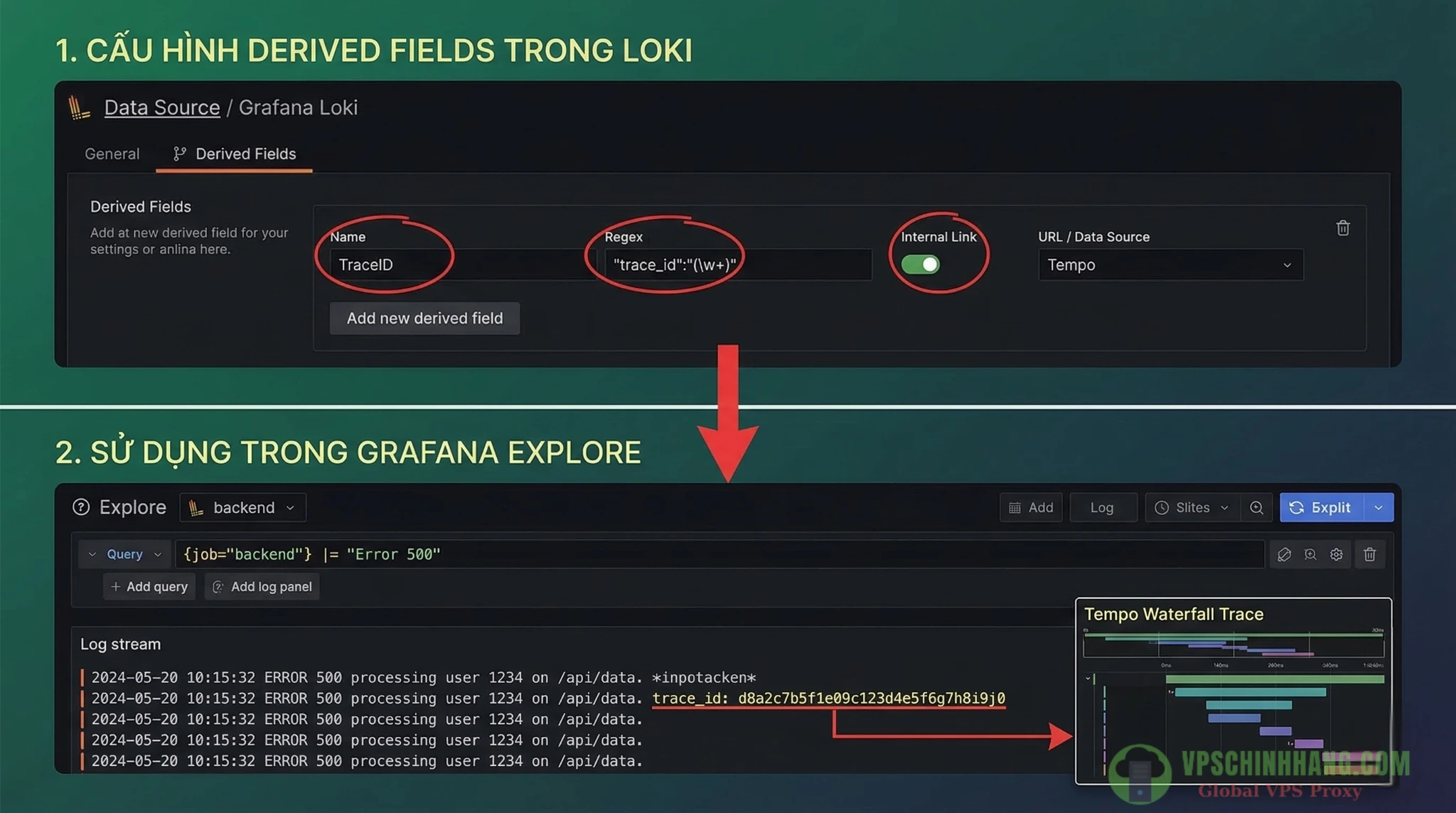
Cấu hình Derived Fields: Biến Trace ID trong log thành nút bấm nhảy thẳng sang giao diện gỡ lỗi Tempo chỉ với 1 cú click chuột.
Kết quả? Bên cạnh dòng log lỗi sẽ xuất hiện một nút bấm. Chỉ 1 cú click, Grafana tự động mở giao diện Tempo, vẽ ra biểu đồ thác nước (waterfall). Bạn sẽ thấy request đó mất 200ms ở API Gateway, và thất bại do một câu query Database bị timeout. Việc khoanh vùng lỗi từ 1 giờ đồng hồ nay rút gọn lại chỉ trong 3 cú click chuột!
Tối ưu hiệu năng VPS & bảo mật pipeline giám sát
Đưa hệ thống lên môi trường Production thực tế đòi hỏi bạn phải có chiến lược tối ưu hiệu năng VPS, nếu không chính công cụ giám sát sẽ tiêu tốn toàn bộ tài nguyên của ứng dụng chính.
Lọc dữ liệu thừa ngay tại nguồn (Filter Processors)
Sử dụng cú pháp OTTL (OpenTelemetry Telemetry Transform Language) trong filter processor để loại bỏ dữ liệu thừa ngay tại Collector, tiết kiệm băng thông và tiền lưu trữ:
processors:
filter/drop_noisy_data:
error_mode: ignore
metrics:
datapoint:
# Loại bỏ metrics của các ổ đĩa ảo tmpfs
- 'metric.name == "system.filesystem.usage" and attributes["system.filesystem.type"] == "tmpfs"'
logs:
log_record:
# Loại bỏ các log ping/healthcheck
- 'IsMatch(body, ".*healthcheck.*")'
Áp dụng Tail-based Sampling cho traces
Trong hệ thống phân tán, lưu trữ 100% traces sẽ làm nổ ổ cứng và cạn kiệt ngân sách. Giải pháp là dùng Tail-based Sampling.
Khác với Head-based (lấy mẫu mù quáng ngay từ đầu request), Tail-based Sampling chờ đến khi toàn bộ trace được tạo ra hoàn chỉnh rồi mới ra quyết định. Nó cung cấp khả năng đãi cát tìm vàng: Hệ thống sẽ vứt bỏ 95% các trace mang mã 200 OK bình thường, nhưng giữ lại 100% các trace bị lỗi, bị crash, hoặc có thời gian phản hồi chậm bất thường. Điều này tối ưu chi phí lưu trữ mà không hề hy sinh khả năng gỡ lỗi.
Bật mTLS để mã hóa dữ liệu đẩy qua Internet
Khi VPS đẩy telemetry data về cụm máy chủ trung tâm qua Internet công cộng, bắt buộc phải thiết lập mTLS (xác thực TLS hai chiều).
Có một lưu ý cực kỳ quan trọng mà rất nhiều kỹ sư cấu hình sai: Thuộc tính client_ca_file phải nằm ở phía Receiver (Máy chủ nhận), chứ không phải Exporter!
- Phía VPS (Exporter) đẩy dữ liệu đi:
exporters:
otlp:
endpoint: myserver.local:4317
tls:
ca_file: /path/to/ca.pem # Xác thực Server
cert_file: /path/to/cert.pem # Chứng chỉ của chính Exporter
key_file: /path/to/cert-key.pem
- Phía Máy chủ trung tâm (Receiver) nhận dữ liệu:
receivers:
otlp:
protocols:
grpc:
tls:
cert_file: /path/to/cert.pem
key_file: /path/to/cert-key.pem
client_ca_file: /path/to/ca.pem # Để xác thực các Exporter gửi lên!
Câu hỏi thường gặp (FAQ)
1. VPS cấu hình yếu (1 CPU, 1GB RAM) chạy OTel Collector có bị quá tải không?
Không, nếu bạn cấu hình giới hạn RAM. Hãy thiết lập memory_limiter processor (ví dụ: giới hạn 256MB) và dùng filter processor để chặn các log/metric thừa. Bản thân OTel Collector Contrib rất nhẹ, chỉ cần bạn không bắt nó xử lý những dữ liệu vô nghĩa.
2. Có thể chạy song song Node Exporter và OTel Collector không?
Được, nhưng gây lãng phí tài nguyên không cần thiết. Thay vì chạy 2 agent, hãy tắt Node Exporter và dùng receiver hostmetrics của OTel. Đối với các ứng dụng nội bộ đang xuất metric chuẩn Prometheus, chỉ cần dùng receiver prometheus trong OTel để thu thập (scrape) dữ liệu. OTel sẽ lo phần còn lại.
3. Làm sao để sửa lỗi PromQL trên Grafana khi chuyển sang OTel?
Cập nhật tên biến theo chuẩn mới hoặc dùng cờ tương thích ngược. Do OTel sử dụng chuẩn Semantic Conventions v1.40.0, tên metric bị đổi (VD: node_cpu_seconds_total thành system.cpu.time).
- Cách nhanh (Giữ dashboard cũ): Bật
resource_to_telemetry_conversion: enabled: truetrong exporter để OTel tự dán nhãn lại giống hệt cấu trúc cũ. - Cách bền vững: Sửa lại PromQL theo chuẩn mới.
4. Quản lý cụm 20 VPS thì giám sát tập trung thế nào?
Cài OTel làm Agent trên từng VPS và đẩy về 1 Backend trung tâm. Bạn cài OTel Collector trên 20 VPS, bật resourcedetection để tự động dán nhãn host.name (tên server). Tất cả Agent sẽ đẩy dữ liệu về một máy chủ trung tâm chạy LGTM Stack. Bạn chỉ cần ngồi 1 chỗ xem Dashboard Grafana là thấy toàn bộ hệ thống.
5. Giữa OTel Collector và Grafana Alloy, tôi nên chọn cái nào?
- Dùng full stack Grafana -> Chọn Alloy.
- Dùng nhiều công cụ trộn lẫn -> Chọn OTel Collector.
Grafana Alloy là bản phân phối tối ưu nhất nếu hạ tầng của bạn cắm rễ vào LGTM (Mimir, Loki, Tempo). Ngược lại, OTel Collector mang tính trung lập, phù hợp nếu bạn muốn đẩy dữ liệu phân tán (VD: Traces lên Datadog, Logs lên Elastic).
6. Không biết code, làm sao để lấy Traces từ ứng dụng trên VPS?
Dùng tính năng Auto-instrumentation (Gắn mã tự động). Bạn không cần sửa source code. Chỉ cần chạy ứng dụng kèm thư viện OTel SDK (hỗ trợ Java, Python, Node.js…), hệ thống sẽ tự động ghi nhận các request HTTP, truy vấn Database và sinh ra Traces đẩy về Collector.
Kết luận
Quyết định triển khai giám sát VPS với OpenTelemetry kết hợp cùng sức mạnh của hệ sinh thái LGTM Stack không chỉ đơn thuần là việc thay đổi một bộ công cụ. Nó là một bước tiến dài, thể hiện tư duy vận hành hạ tầng DevOps hiện đại: từ việc vật lộn với các mảng dữ liệu phân mảnh mờ mịt, sang việc làm chủ toàn bộ vòng đời của hệ thống một cách trơn tru, sắc nét.
Bằng cách triển khai OTel Collector v0.147.0, nắm vững nguyên lý Semantic Conventions v1.40.0 và áp dụng các mẹo cấu hình từ chuyên gia, bạn sẽ giải quyết triệt để bài toán hao tốn tài nguyên máy chủ, xóa bỏ rào cản vendor lock-in, và tối ưu hóa thời gian xử lý sự cố (MTTR) một cách ngoạn mục.
Tài liệu tham khảo
- Release v0.147.0 · open-telemetry/opentelemetry-collector-contrib · GitHub
- Metrics semantic conventions | OpenTelemetry
- From Agent to Alloy: Why we transitioned to the Alloy collector and why you should, too | Grafana Labs
- PromLabs | Blog – Why I recommend native Prometheus instrumentation over OpenTelemetry
- Configure the Loki data source | Grafana documentation