


Hướng dẫn cấu hình Alertmanager cho Prometheus
Sau khi đã triển khai Prometheus để thu thập metrics và Grafana để trực quan hóa, bước tiếp theo và cũng không kém phần quan trọng là thiết lập hệ thống cảnh báo tự động. Alertmanager là mảnh ghép cuối cùng giúp bạn nhận được thông báo kịp thời khi có bất kỳ sự cố nào xảy ra với VPS của mình. Bài viết này sẽ hướng dẫn bạn cách cài đặt và cấu hình Alertmanager, thiết lập các luật cảnh báo trong Prometheus và cách gửi thông báo đến các kênh mà bạn mong muốn.
Giới thiệu Alertmanager và tầm quan trọng của cảnh báo
Alertmanager là gì?
Alertmanager là một thành phần riêng biệt trong hệ sinh thái Prometheus, được thiết kế chuyên biệt để xử lý các cảnh báo được Prometheus gửi đến. Vai trò cốt lõi của nó bao gồm:
- Nhóm (Grouping): Nhóm các cảnh báo tương tự lại với nhau để tránh gửi quá nhiều thông báo cho một sự cố. Ví dụ, nếu 100 máy chủ đều gặp vấn đề về CPU, Alertmanager sẽ nhóm chúng lại thành một thông báo duy nhất.
- Định tuyến (Routing): Gửi các cảnh báo đến đúng người hoặc đúng kênh thông báo dựa trên nhãn (labels) của cảnh báo.
- Giảm nhiễu (Deduplication): Đảm bảo mỗi cảnh báo chỉ được gửi một lần và không lặp lại quá thường xuyên.
- Ngăn chặn (Silencing): Cho phép bạn tạm thời tắt cảnh báo cho một số sự cố nhất định khi bạn đang tiến hành bảo trì hoặc biết về một vấn đề.
- Gửi thông báo (Notification): Hỗ trợ nhiều kênh thông báo phổ biến như email, Slack, PagerDuty, Webhook và nhiều hơn nữa.
Tại sao cần cảnh báo?
Việc có một hệ thống cảnh báo tự động là tối quan trọng trong quản lý máy chủ:
- Phản ứng kịp thời: Nhận biết ngay lập tức các vấn đề như CPU quá tải, bộ nhớ đầy, ổ đĩa cạn kiệt, dịch vụ ngừng hoạt động, giúp bạn khắc phục sự cố trước khi chúng ảnh hưởng đến người dùng.
- Giảm thiểu downtime: Các cảnh báo sớm giúp giảm thiểu thời gian ngừng hoạt động của dịch vụ, bảo vệ danh tiếng và hoạt động kinh doanh của bạn.
- Chủ động quản lý: Thay vì phải liên tục kiểm tra dashboard, bạn có thể tự tin rằng mình sẽ được thông báo khi có vấn đề cần can thiệp.
Luồng cảnh báo tổng thể
Quy trình một cảnh báo được xử lý diễn ra như sau: Prometheus -> Alertmanager -> Kênh thông báo
- Prometheus: Thu thập metrics và đánh giá các luật cảnh báo (Alerting Rules). Khi một luật cảnh báo được kích hoạt (điều kiện được thỏa mãn), Prometheus sẽ tạo ra một cảnh báo.
- Alertmanager: Prometheus gửi cảnh báo này đến Alertmanager. Alertmanager tiếp nhận, nhóm các cảnh báo tương tự, xử lý theo các quy tắc định tuyến, và áp dụng các cấu hình về silence hay deduplication.
- Kênh thông báo: Cuối cùng, Alertmanager sẽ gửi thông báo cảnh báo đến kênh đã cấu hình (email, Slack, Telegram…).
Chuẩn bị cài đặt Alertmanager
Trước khi bắt đầu, hãy đảm bảo VPS của bạn đáp ứng các yêu cầu sau:
- Hệ điều hành: Linux (Ubuntu 20.04+ hoặc CentOS 7+).
- Quyền truy cập: Quyền
roothoặc người dùng có quyềnsudo. - Cổng cần mở:
- Cổng 9093: Đây là cổng mặc định mà Alertmanager sử dụng cho giao diện web UI và API. Bạn cần đảm bảo cổng này được mở trong tường lửa của VPS.
- Ví dụ mở cổng với UFW (Ubuntu):
sudo ufw allow 9093/tcp
sudo ufw reload
-
- Ví dụ mở cổng với Firewalld (CentOS):
sudo firewall-cmd --permanent --add-port=9093/tcp
sudo firewall-cmd --reload
- Kiểm tra Prometheus: Đảm bảo Prometheus Server đang chạy và thu thập dữ liệu.
Cài đặt Alertmanager trên VPS Linux
Tải về Alertmanager
Truy cập trang GitHub chính thức của Alertmanager để tìm phiên bản ổn định mới nhất. Bạn có thể sử dụng wget để tải trực tiếp về VPS của mình.
# Tạo thư mục để lưu trữ các file tạm
mkdir -p /opt/alertmanager/temp && cd /opt/alertmanager/temp
# Tải về phiên bản Alertmanager mới nhất
# Luôn kiểm tra phiên bản mới nhất tại: https://github.com/prometheus/alertmanager/releases
# Ví dụ, nếu phiên bản mới nhất là v0.28.1:
wget https://github.com/prometheus/alertmanager/releases/download/v0.28.1/alertmanager-0.28.1.linux-amd64.tar.gz
Lưu ý: Luôn kiểm tra và thay thế v0.28.1 bằng phiên bản Alertmanager ổn định mới nhất tại thời điểm bạn thực hiện tại Alertmanager Releases.
Giải nén và cấu hình thư mục/quyền
Sau khi tải về, chúng ta sẽ giải nén và di chuyển các file cần thiết, đồng thời tạo một người dùng riêng và các thư mục cấu hình/dữ liệu cho Alertmanager.
# Giải nén file đã tải về
tar xvfz alertmanager-0.28.1.linux-amd64.tar.gz
# Di chuyển file thực thi alertmanager và amtool vào /usr/local/bin
sudo mv alertmanager-0.28.1.linux-amd64/alertmanager /usr/local/bin/
sudo mv alertmanager-0.28.1.linux-amd64/amtool /usr/local/bin/
# Tạo thư mục cấu hình và dữ liệu cho Alertmanager
sudo mkdir -p /etc/alertmanager
sudo mkdir -p /var/lib/alertmanager
# Tạo người dùng hệ thống alertmanager (không có quyền đăng nhập)
sudo useradd -rs /bin/false alertmanager
# Gán quyền sở hữu cho các thư mục và file
sudo chown -R alertmanager:alertmanager /etc/alertmanager
sudo chown -R alertmanager:alertmanager /var/lib/alertmanager
sudo chown alertmanager:alertmanager /usr/local/bin/alertmanager
sudo chown alertmanager:alertmanager /usr/local/bin/amtool
# Xóa thư mục tạm thời
rm -rf alertmanager-0.27.0.linux-amd64/
Tạo Service Unit cho Alertmanager (Systemd)
Để Alertmanager có thể chạy như một dịch vụ nền và tự động khởi động cùng hệ thống, chúng ta sẽ tạo một file service unit cho Systemd:
sudo nano /etc/systemd/system/alertmanager.service
Thêm nội dung sau vào file:
[Unit]
Description=Alertmanager
Wants=network-online.target
After=network-online.target
[Service]
User=alertmanager
Group=alertmanager
Type=simple
ExecStart=/usr/local/bin/alertmanager \
--config.file /etc/alertmanager/alertmanager.yml \
--storage.path /var/lib/alertmanager
[Install]
WantedBy=multi-user.target
ExecStart: Chỉ định đường dẫn đến file thực thi của Alertmanager và các tham số khởi động:--config.file: Đường dẫn đến file cấu hình chínhalertmanager.yml.--storage.path: Đường dẫn nơi Alertmanager lưu trữ dữ liệu.
User=alertmanagervàGroup=alertmanager: Đảm bảo Alertmanager chạy dưới người dùngalertmanagermà chúng ta đã tạo, tăng cường bảo mật.
Lưu file và thoát (Ctrl+X, Y, Enter).
Khởi động và kiểm tra Alertmanager
Bây giờ, chúng ta sẽ tải lại cấu hình Systemd, khởi động Alertmanager và kiểm tra trạng thái của nó:
sudo systemctl daemon-reload
sudo systemctl start alertmanager
sudo systemctl enable alertmanager # Tự động khởi động cùng hệ thống
sudo systemctl status alertmanager
Nếu mọi thứ đều đúng, bạn sẽ thấy trạng thái active (running).
Cấu hình Alertmanager (alertmanager.yml) để gửi thông báo
File alertmanager.yml là trái tim của Alertmanager, nơi bạn định nghĩa cách các cảnh báo được nhóm, định tuyến và gửi đi.
Tổng quan về alertmanager.yml
Một file alertmanager.yml cơ bản bao gồm các phần chính:
global: Cấu hình chung cho Alertmanager (ví dụ:resolve_timeout– thời gian chờ trước khi một cảnh báo được coi là đã được giải quyết).route: Định nghĩa cấu trúc định tuyến cảnh báo. Đây là một cây cấu trúc, vớiroutegốc là nơi mọi cảnh báo đi vào, sau đó phân nhánh dựa trên các điều kiện (nhãn của cảnh báo) đến cácreceivercụ thể.receivers: Định nghĩa các kênh thông báo nơi cảnh báo sẽ được gửi đến (email, Slack, webhook…).templates: (Nâng cao) Định nghĩa các mẫu tùy chỉnh cho nội dung thông báo.
Tạo file cấu hình alertmanager.yml
sudo nano /etc/alertmanager/alertmanager.yml
Ví dụ cấu hình alertmanager.yml với Email (SMTP)
Đây là một ví dụ cấu hình cơ bản để gửi cảnh báo qua email. Bạn cần thay thế các thông tin smtp_smarthost, smtp_from, to, smtp_auth_username, smtp_auth_password bằng thông tin SMTP của bạn.
global:
resolve_timeout: 5m # Thời gian chờ trước khi một cảnh báo được coi là đã giải quyết
route:
group_by: ['alertname', 'instance'] # Nhóm cảnh báo theo tên cảnh báo và instance
group_wait: 30s # Thời gian chờ ban đầu trước khi gửi thông báo nhóm
group_interval: 5m # Khoảng thời gian giữa các thông báo nhóm liên tiếp
repeat_interval: 4h # Khoảng thời gian để lặp lại thông báo nếu cảnh báo vẫn tồn tại
receiver: 'default-receiver' # Cấu hình receiver mặc định nếu không có rule nào phù hợp
receivers:
- name: 'default-receiver'
email_configs:
- to: '[email protected]' # Địa chỉ email nhận cảnh báo
from: '[email protected]' # Địa chỉ email gửi cảnh báo
smarthost: 'smtp.your-email-provider.com:587' # Máy chủ SMTP của bạn (ví dụ: smtp.gmail.com:587)
auth_username: '[email protected]' # Tên đăng nhập SMTP
auth_password: 'your_smtp_password' # Mật khẩu SMTP (CẨN TRỌNG: KHÔNG NÊN ĐẶT MẬT KHẨU TRỰC TIẾP TRONG FILE THỰC TẾ TRÊN MÔI TRƯỜNG PRODUCTION. HÃY DÙNG CÁC PHƯƠNG PHÁP QUẢN LÝ BÍ MẬT)
# html: 'true' # Có thể gửi email định dạng HTML
# Nếu bạn muốn cấu hình các receiver khác (ví dụ: Slack, Telegram), chúng sẽ được thêm vào đây.
# Ví dụ về receiver Slack (chỉ minh họa, không đi sâu vào chi tiết cấu hình)
#- name: 'slack-receiver'
# slack_configs:
# - channel: '#alerts'
# api_url: 'https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX'
smarthost: Địa chỉ máy chủ SMTP và cổng của nhà cung cấp dịch vụ email của bạn (ví dụ:smtp.gmail.com:587cho Gmail, bạn có thể cần tạo mật khẩu ứng dụng).auth_usernamevàauth_password: Thông tin xác thực để gửi email qua máy chủ SMTP.- Cảnh báo bảo mật: Việc đặt mật khẩu trực tiếp trong file cấu hình là không an toàn, đặc biệt trong môi trường sản phẩm (production). Đối với môi trường thực tế, hãy sử dụng các giải pháp quản lý bí mật (secret management) như Vault hoặc các biến môi trường để cấp phát thông tin nhạy cảm.
Lưu file và thoát.
Kiểm tra cú pháp alertmanager.yml
Để đảm bảo file cấu hình của bạn không có lỗi cú pháp, hãy sử dụng công cụ amtool:
/usr/local/bin/amtool check-config /etc/alertmanager/alertmanager.yml
Nếu không có lỗi, bạn sẽ thấy thông báo “Config file is valid”.
Tải lại cấu hình Alertmanager
Sau khi thay đổi file alertmanager.yml, bạn cần tải lại cấu hình để Alertmanager áp dụng các thay đổi:
sudo systemctl reload alertmanager
Thiết lập Alerting Rules (Luật cảnh báo) trong Prometheus
Alerting Rules là các biểu thức PromQL được Prometheus đánh giá định kỳ. Nếu một biểu thức trả về giá trị thỏa mãn điều kiện trong một khoảng thời gian nhất định, Prometheus sẽ kích hoạt một cảnh báo và gửi nó đến Alertmanager.
Khái niệm Alerting Rules
Mỗi Alert Rule định nghĩa:
- Tên cảnh báo (
alert): Tên duy nhất của cảnh báo. - Biểu thức (
expr): Biểu thức PromQL mà Prometheus sẽ đánh giá. - Thời gian (
for): Khoảng thời gian mà biểu thức phải đúng trước khi cảnh báo được kích hoạt. Điều này giúp tránh các cảnh báo giả do biến động ngắn hạn. - Nhãn (
labels): Các cặp khóa-giá trị được gắn vào cảnh báo, dùng để định tuyến và nhóm cảnh báo trong Alertmanager. - Chú thích (
annotations): Thông tin mô tả thêm về cảnh báo, thường được hiển thị trong thông báo (summary, description).
Tạo thư mục và file Rule
Chúng ta sẽ tạo một thư mục riêng cho các file rule và một file ví dụ cho cảnh báo CPU.
# Tạo thư mục cho các file rule của Prometheus
sudo mkdir -p /etc/prometheus/rules
# Tạo file rule ví dụ cho CPU usage
sudo nano /etc/prometheus/rules/cpu_alerts.yml
Thêm nội dung sau vào file cpu_alerts.yml:
groups:
- name: HostAlerts # Tên nhóm luật cảnh báo
rules:
- alert: HighCpuUsage # Tên cảnh báo
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 5m # Cảnh báo sẽ được kích hoạt nếu CPU > 80% trong 5 phút liên tục
labels:
severity: critical # Nhãn mức độ nghiêm trọng: critical, warning, info
annotations:
summary: "CPU usage on {{ $labels.instance }} is high" # Tiêu đề của thông báo
description: "CPU usage has been above 80% for 5 minutes. Current value: {{ $value }}%" # Mô tả chi tiết trong thông báo
expr: Biểu thức này tính toán phần trăm CPU đang được sử dụng (không bao gồm thời gian idle).for: 5m: Cảnh báo chỉ được coi là kích hoạt nếu điều kiệnexprđúng trong 5 phút liên tục. Nếu CPU giảm xuống dưới 80% trong 5 phút đó, cảnh báo sẽ không được gửi.
Ví dụ một số Alert Rules phổ biến khác
Bạn có thể thêm các rule tương tự vào cùng file cpu_alerts.yml hoặc tạo các file .yml riêng biệt cho từng loại cảnh báo (ví dụ: memory_alerts.yml, disk_alerts.yml).
# ... (Tiếp theo trong file cpu_alerts.yml hoặc file rule khác)
- alert: LowMemoryAvailable
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 15
for: 5m
labels:
severity: warning
annotations:
summary: "Low memory available on {{ $labels.instance }}"
description: "Available memory on {{ $labels.instance }} is below 15%. Current value: {{ $value | humanize }}%"
- alert: HighDiskUsage
expr: 100 - (node_filesystem_avail_bytes{fstype="ext4", mountpoint="/"} / node_filesystem_size_bytes{fstype="ext4", mountpoint="/"} * 100) > 90
for: 5m
labels:
severity: critical
annotations:
summary: "High disk usage on {{ $labels.instance }}"
description: "Disk usage on {{ $labels.instance }} for mountpoint / is above 90%. Current value: {{ $value }}%"
- alert: NodeExporterDown
expr: up{job="node_exporter"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Node Exporter is down on {{ $labels.instance }}"
description: "Node Exporter on {{ $labels.instance }} is unreachable. Metrics are not being collected."
Lưu file và thoát.
Tích hợp Alert Rules và Alertmanager với Prometheus
Để Prometheus biết về các Alert Rules bạn vừa tạo và nơi để gửi cảnh báo, bạn cần cập nhật file cấu hình prometheus.yml.
Cấu hình Prometheus để đọc Alert Rules
Mở file cấu hình prometheus.yml của Prometheus:
sudo nano /etc/prometheus/prometheus.yml
Thêm dòng sau vào phần global hoặc một vị trí phù hợp trong file (đảm bảo đúng định dạng YAML):
# ... các cấu hình khác của Prometheus ...
rule_files:
- "/etc/prometheus/rules/*.yml" # Prometheus sẽ đọc tất cả các file .yml trong thư mục này
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093 # Địa chỉ của Alertmanager
# ... các scrape_configs của bạn ...
rule_files: Chỉ định đường dẫn đến các file chứa Alert Rules. Dòng này sẽ hướng dẫn Prometheus tải tất cả các file.ymltrong thư mục/etc/prometheus/rules/.alerting: Phần này cấu hình Prometheus để biết nơi gửi các cảnh báo đã được kích hoạt.alertmanagers: Danh sách các instance Alertmanager.targets: Địa chỉ của Alertmanager của bạn (trong trường hợp này làlocalhost:9093vì nó chạy trên cùng VPS).
Lưu file và thoát.
Tải lại cấu hình Prometheus
Sau khi thay đổi file prometheus.yml, bạn cần tải lại cấu hình để Prometheus áp dụng các thay đổi mới, bao gồm việc đọc các Alert Rules và biết nơi để gửi cảnh báo:
sudo systemctl reload prometheus
Lệnh này sẽ tải lại cấu hình mà không làm dừng Prometheus, đảm bảo việc giám sát không bị gián đoạn.
Kiểm tra và xác nhận cảnh báo
Sau khi mọi thứ đã được cấu hình, việc kiểm tra là rất quan trọng để đảm bảo cảnh báo hoạt động đúng như mong đợi.
Kiểm tra trạng thái trên giao diện Prometheus
Truy cập giao diện web của Prometheus (http://<IP_VPS_Của_Bạn>:9090).
- Điều hướng đến mục “Alerts” trên thanh điều hướng.
- Bạn sẽ thấy danh sách các Alert Rules đã được tải. Kiểm tra cột “State” để xem chúng đang ở trạng thái nào (ví dụ:
inactive,pending,firing).
Truy cập giao diện Alertmanager Web UI
Truy cập giao diện web của Alertmanager (http://<IP_VPS_Của_Bạn>:9093).
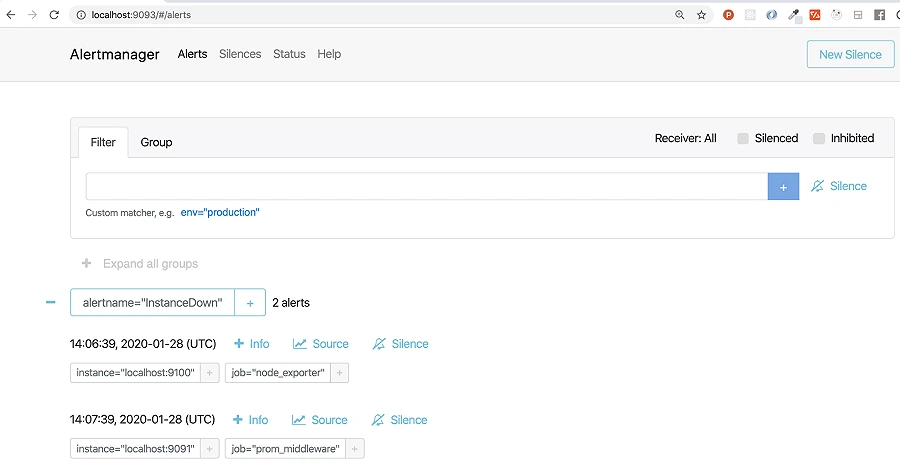
Alertmanager Alerts
- Tab “Alerts”: Hiển thị các cảnh báo đang hoạt động (
Firing) hoặc đã được giải quyết (Resolved). Khi có cảnh báo được kích hoạt, bạn sẽ thấy nó xuất hiện ở đây. - Tab “Silences”: Nơi bạn có thể tạo các “silence” để tạm thời tắt cảnh báo cho một số vấn đề nhất định.
- Tab “Status”: Hiển thị trạng thái chung của Alertmanager, bao gồm các receiver và cấu hình.
Kiểm tra cảnh báo thực tế (Tùy chọn)
Để kiểm tra xem cảnh báo có được gửi đi không, bạn cần tạo một điều kiện để kích hoạt một trong các rule bạn đã định nghĩa:
- Để kích hoạt
HighCpuUsage:
Bạn có thể cài đặt công cụstress-ngvà chạy nó để tăng tải CPU:
sudo apt install stress-ng -y # Ubuntu/Debian
# hoặc sudo yum install stress-ng -y # CentOS/RHEL
stress-ng --cpu 4 --cpu-method matrixprod --timeout 300s # Tăng tải 4 core CPU trong 300s
Theo dõi CPU usage trên dashboard Grafana hoặc Prometheus. Nếu nó duy trì trên 80% trong 5 phút, cảnh báo sẽ được kích hoạt.
- Để kích hoạt
NodeExporterDown:
Tạm thời dừng dịch vụ Node Exporter:
sudo systemctl stop node_exporter
Cảnh báo sẽ được kích hoạt sau 1 phút nếu Node Exporter không thể truy cập được. Đừng quên khởi động lại nó sau khi kiểm tra: sudo systemctl start node_exporter.
Sau khi cảnh báo được kích hoạt (trạng thái Firing trong Prometheus và Alertmanager UI), hãy kiểm tra hộp thư email hoặc kênh thông báo mà bạn đã cấu hình trong alertmanager.yml. Bạn sẽ nhận được thông báo cảnh báo.
Kết luận
Bạn đã thành công trong việc thiết lập một hệ thống cảnh báo tự động mạnh mẽ cho VPS Linux của mình bằng Prometheus và Alertmanager. Từ việc cài đặt Alertmanager, cấu hình cách nó gửi thông báo qua email, cho đến việc định nghĩa các luật cảnh báo trong Prometheus để nhận biết các vấn đề về CPU, RAM, ổ đĩa và dịch vụ.
Hệ thống này sẽ giúp bạn chủ động hơn rất nhiều trong việc quản lý và duy trì sự ổn định của VPS, cho phép bạn phản ứng nhanh chóng với mọi sự cố.
Bạn có thể tiếp tục khám phá các tính năng nâng cao hơn của Alertmanager như:
- Cấu hình các receiver phức tạp hơn (Slack, Telegram, PagerDuty…) để tích hợp vào quy trình làm việc của nhóm.
- Tinh chỉnh các
routeđể gửi cảnh báo đến các nhóm khác nhau dựa trên mức độ nghiêm trọng hoặc loại cảnh báo. - Sử dụng “silence” để tạm thời tắt cảnh báo trong quá trình bảo trì.
Nguồn tham khảo
- Trang chủ Alertmanager: https://prometheus.io/docs/alerting/latest/alertmanager/
- GitHub Alertmanager Releases: https://github.com/prometheus/alertmanager/releases
- Prometheus Alerting Rules: https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
- Amtool (Alertmanager Tool): https://prometheus.io/docs/alerting/latest/alertmanager/#using-amtool
Giải cứu ổ C Windows Server 2025: Cách dùng lệnh PowerShell dọn dẹp ổ đĩa tự động, an toàn

Giải pháp chống sập Server: Dùng script PowerShell giám sát VPS và bắn cảnh báo Telegram







