Cách xây dựng hệ thống thu thập dữ liệu thị trường với VPS và Proxy minh bạch, hợp pháp
Cắm máy chạy script thu thập dữ liệu qua đêm, sáng hôm sau hăm hở mở file CSV lên kiểm tra thì rỗng tuếch. Màn hình console báo lỗi đỏ rực: HTTP 429 Too Many Requests, hoặc tệ hơn là dính Timeout vì IP nhà mạng của bạn đã bị website đưa thẳng vào danh sách đen (block IP).
Nếu bạn là một Data Analyst, Marketer hay kỹ sư dữ liệu, chắc chắn kịch bản sập mạng, kẹt tài nguyên hay API bị rate-limit này không hề xa lạ. Việc tận dụng máy tính cá nhân để trích xuất thông tin hàng nghìn trang sản phẩm hay tin tức không chỉ vắt kiệt phần cứng mà còn bộc lộ sự thiếu chuyên nghiệp trong việc quản lý luồng request. Nã hàng ngàn truy vấn từ một IP hộ gia đình chẳng khác nào một cuộc tấn công DDoS vô ý, khiến hệ thống bảo mật của đối phương buộc phải tự vệ.
Nhưng làm thế nào để chuyển dịch và xây dựng một hệ thống thu thập dữ liệu thị trường với VPS vừa chịu tải tốt, lại vừa đảm bảo đạo đức, minh bạch và tuân thủ các nguyên tắc kỹ thuật? Cùng bóc tách quy trình chuẩn kỹ sư qua bài viết thực chiến dưới đây.
Tại sao nên chuyển đổi hệ thống thu thập dữ liệu thị trường với VPS?
Chuyển đổi hạ tầng không đơn thuần là thuê một máy chủ rồi đưa code lên đó chạy. Đó là bước nâng cấp từ làm thủ công lên một Data Pipeline chuyên nghiệp, nơi mọi thứ được kiểm soát chặt chẽ và có khả năng scale không giới hạn.
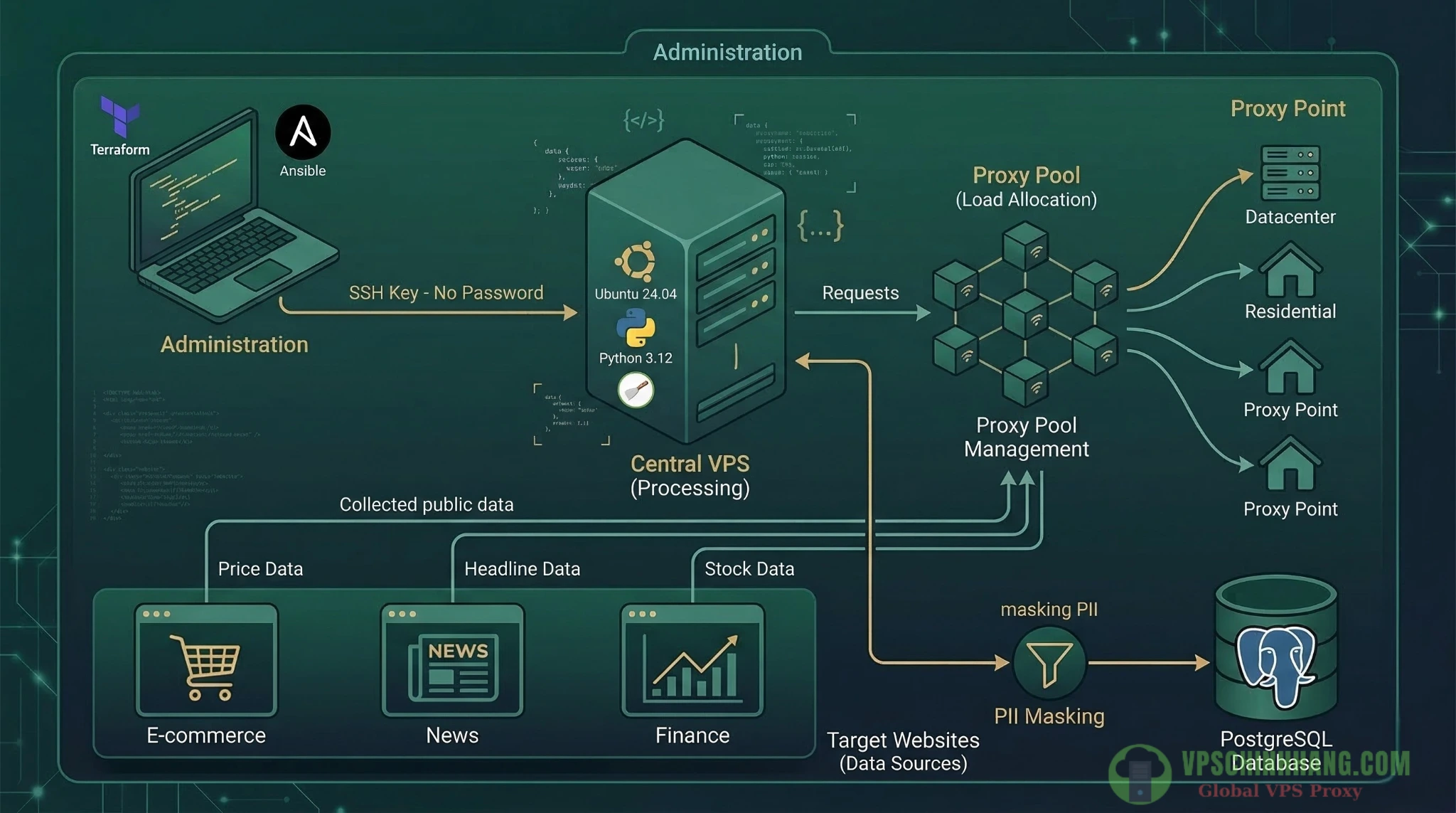
Sơ đồ kiến trúc luồng dữ liệu chuẩn DataOps, sử dụng IaC để quản trị VPS và Proxy Pool để phân bổ tải request đến website mục tiêu.
Đảm bảo uptime 24/7 và thoát cảnh giật lag máy cá nhân
Khác với máy tính cá nhân bị ảnh hưởng bởi thói quen sử dụng, chế độ Sleep, hay tình trạng mất kết nối cục bộ, VPS nằm trong các Data Center tiêu chuẩn với đường truyền quốc tế tốc độ cao (nếu bạn chưa rõ sự khác biệt cốt lõi, hãy tham khảo bài viết Cloud VPS là gì? So sánh ưu điểm của Cloud VPS và VPS vật lý thông thường).
Hệ thống của bạn sẽ chạy xuyên suốt 24/7. Điều này cực kỳ quan trọng nếu bạn cần thu thập biến động giá theo giờ (real-time tracking) trên các sàn thương mại điện tử, hay thiết lập cronjob chạy vào các khung giờ thấp điểm (2h đến 4h sáng) để không gây áp lực lên server mục tiêu.
Hơn nữa, khi chạy các công cụ render JavaScript nặng như Playwright hay Selenium, việc Chrome sử dụng cạn kiệt bộ nhớ và làm tràn RAM (Memory Leak) là chuyện diễn ra thường xuyên. Với VPS, bạn có một môi trường độc lập (isolated environment), script thu thập dữ liệu hoạt động tách biệt hoàn toàn với không gian làm việc cá nhân của bạn.
Quản trị hạ tầng bằng mã (Infrastructure as Code) với Terraform và Ansible
Trong thực tế, khi nhu cầu thu thập dữ liệu tăng vọt (ví dụ cần rà soát hàng trăm ngàn URL mỗi ngày), một VPS là không đủ. Bạn sẽ cần triển khai một cụm (cluster) gồm nhiều VPS chạy song song. Nếu SSH vào từng server gõ lệnh apt update rồi cài đặt thư viện thủ công thì bạn sẽ nhanh chóng bị quá tải, đồng thời dễ gặp tình trạng chống trôi dạt cấu hình (Configuration Drift), nơi mỗi server lại chạy một phiên bản thư viện khác nhau gây lỗi.
Giải pháp thực chiến ở đây là áp dụng Infrastructure as Code (IaC):
- Terraform: Dùng để khởi tạo hạ tầng. Bạn chỉ cần khai báo cấu hình mong muốn, Terraform sẽ tự động gọi API của nhà cung cấp (như DigitalOcean, Vultr, Linode) để tạo ra hàng loạt Droplets/Instances, cấu hình mạng và gắn IP trong vài giây.
- Ansible: Dùng để quản lý cấu hình bên trong hệ điều hành. Sau khi Terraform chạy xong, Ansible sẽ tự động SSH vào các VPS này để tạo user, thiết lập tường lửa, cài đặt môi trường Python và triển khai code trích xuất thông tin một cách đồng nhất. Mọi máy chủ đều tuân thủ chính xác một thiết kế ban đầu, giúp bạn dễ dàng scale out hoặc phục hồi hệ thống khi có sự cố.
Bảo mật hạ tầng VPS theo kiến trúc Zero Trust (NIST SP 800-207)
Nhiều người lầm tưởng bảo mật VPS chỉ đơn giản là dựng một lớp tường lửa bên ngoài rồi tin tưởng hoàn toàn mọi kết nối bên trong mạng nội bộ. Đây là tư duy phòng thủ vành đai (perimeter defense) đã lỗi thời.
Theo tài liệu chuẩn NIST SP 800-207, mô hình Zero Trust được xây dựng trên nguyên lý cốt lõi: Không bao giờ ngầm định cấp quyền tin cậy (trust is never granted implicitly). Vị trí mạng của một tài sản (dù nằm trong LAN) không tự động hàm ý sự tin cậy. Bạn phải luôn giả định rằng môi trường mạng đã bị xâm phạm và kẻ tấn công có thể đang lẩn khuất ngay bên trong hệ thống.
Để hiểu sâu hơn về cách setup thực tiễn trên máy chủ, bạn có thể xem qua bài Cách triển khai mô hình Zero Trust trên VPS để chặn đứng tấn công mạng (2026).
Áp dụng tư tưởng Zero Trust vào việc quản trị VPS thu thập dữ liệu, chúng ta có các bước thực chiến sau:
- Chỉ sử dụng SSH Key, cấm Password: Việc mở port 22 với xác thực bằng mật khẩu là rủi ro lớn cho các botnet tấn công dò tìm (brute-force). Hãy bắt buộc xác thực bằng cặp khóa mã hóa SSH Key và thiết lập
PasswordAuthentication notrong cấu hình sshd.- Dành cho người mới: SSH là gì? Download bộ cài SSH client mới nhất.
- Đặc quyền tối thiểu (Least Privilege): Không bao giờ dùng tài khoản
rootđể chạy script thu thập dữ liệu. Hãy tạo một user tiêu chuẩn (non-root) và chỉ cấp quyềnsudokhi bảo trì. Đồng thời, thiết lậpPermitRootLogin nođể chặn đứng nỗ lực chiếm quyền cao nhất. - Tường lửa Explicit Deny: Cấu hình UFW hoặc iptables từ chối tất cả các kết nối đến theo mặc định. Chỉ chủ động mở các port thực sự cần thiết.
- Cấp quyền theo từng phiên (Per-session basis): Sự tin cậy phải được đánh giá lại liên tục. Nếu hệ thống của bạn cần ghi dữ liệu vào PostgreSQL trên một VPS khác, hãy phân quyền user database chỉ có lệnh
INSERT, không có quyềnDROPhayALTER.
Tích hợp Proxy vào VPS: Phân bổ tải thông minh và quản lý luồng truy vấn
Trong kỹ thuật thu thập dữ liệu, Proxy đóng vai trò như một bộ cân bằng tải phân tán (Distributed Load Balancer) chuyên dụng.
Thay vì gửi hàng ngàn request từ một địa chỉ IP duy nhất (điều chắc chắn sẽ làm nghẽn cổ chai mạng nội bộ và bị máy chủ đích chặn do vi phạm giới hạn tỷ lệ), việc điều hướng lưu lượng qua một Proxy Pool giúp phân tán các yêu cầu này một cách nhịp nhàng.
Đặc biệt, với các chiến dịch cần quy mô lớn, bạn có thể cân nhắc giải pháp Proxy IPv6 là gì? Cách thiết lập Proxy IPv6 trên VPS Linux scale triệu IP (2026).
Proxy Datacenter vs Proxy Residential
- Proxy Datacenter (Trung tâm dữ liệu): Là các IP được tạo ra bởi các dịch vụ đám mây. Chúng có tốc độ cực kỳ nhanh và chi phí hợp lý. Tuy nhiên, dải IP này rất dễ bị các hệ thống WAF nhận diện. Phù hợp để lấy dữ liệu từ các trang web công khai có lớp bảo mật cơ bản.
- Proxy Residential (Dân cư): Cung cấp các địa chỉ IP thực được cấp bởi ISP. IP này có độ tin cậy cao, giúp bạn truy cập trơn tru các dữ liệu hiển thị theo vị trí địa lý (Geolocation Pricing) mà không bị gián đoạn.
Xử lý triệt để mã lỗi HTTP 429: Đừng vội dùng Exponential Backoff!
Rất nhiều kỹ sư khi thấy script báo lỗi 429 Too Many Requests liền lập tức áp dụng thuật toán Exponential Backoff (lùi bước theo hàm mũ: chờ 2s, 4s, 8s…). Tuy nhiên, theo tài liệu chuẩn từ MDN Web Docs, đây chưa phải là cách xử lý tối ưu nhất.
Lỗi 429 là cơ chế giới hạn tỷ lệ (rate-limit) của máy chủ đích. MDN Web Docs chỉ rõ rằng, phản hồi 429 thường đi kèm với một header cực kỳ quan trọng: Retry-After. Header này chứa thông báo chính xác khoảng thời gian (tính bằng giây hoặc một mốc ngày giờ) mà máy chủ yêu cầu bạn phải chờ trước khi gửi request tiếp theo.
Cách giải quyết chuẩn kỹ sư: Code của bạn phải luôn parse (phân tích) header của response đầu tiên. Nếu có Retry-After: 3600, hệ thống phải chủ động đưa worker đó vào trạng thái sleep đúng 60 phút. Chỉ trong trường hợp website đích trả về lỗi 429 nhưng không cung cấp header Retry-After, bạn mới bắt đầu áp dụng cơ chế dự phòng như Exponential Backoff kết hợp luân phiên Proxy để tránh làm gián đoạn luồng truy vấn.
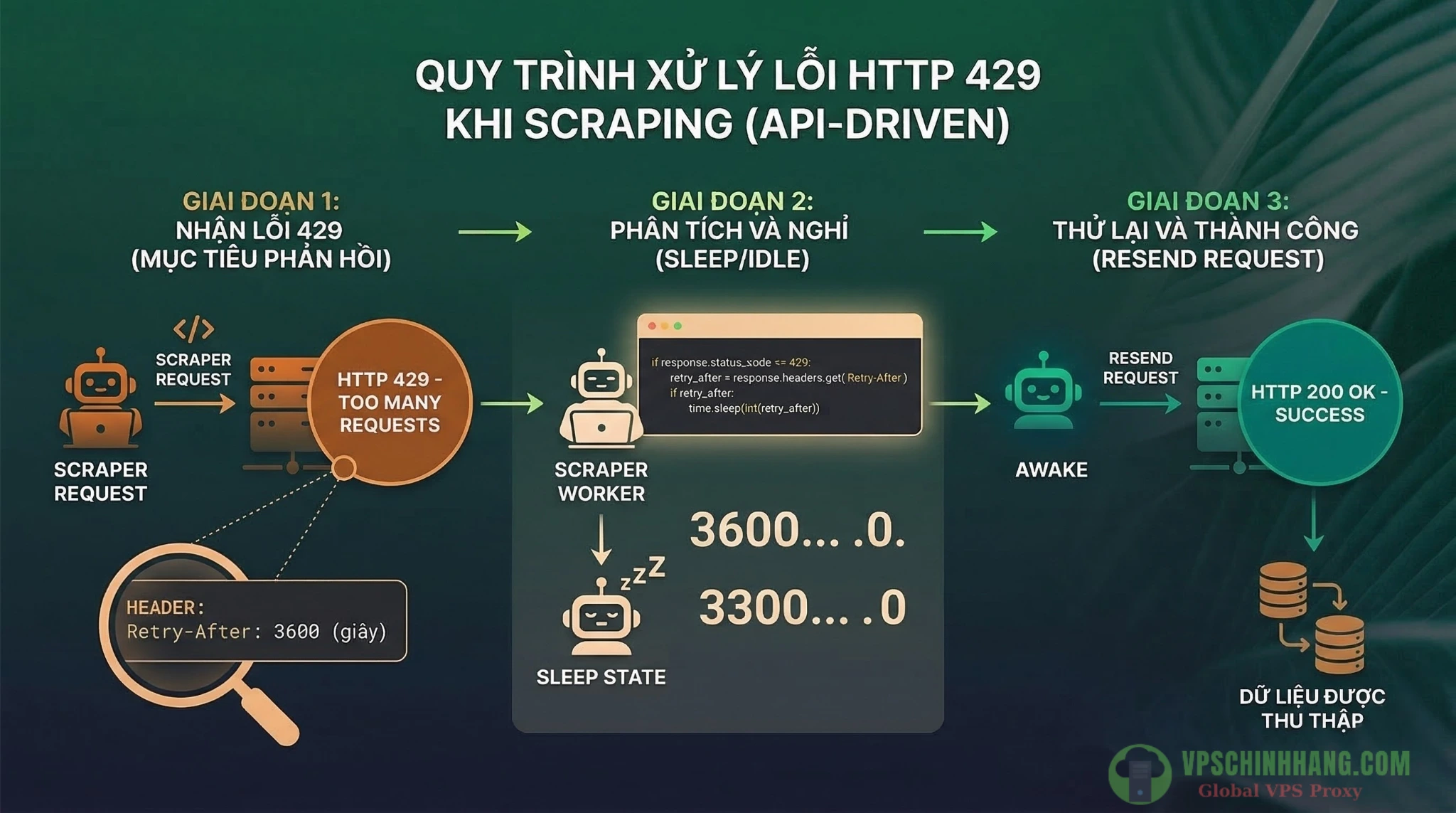
Quy trình 3 bước chuẩn kỹ sư để xử lý mã lỗi 429 Too Many Requests, ưu tiên tuân thủ header Retry-After để duy trì luồng thu thập dữ liệu.
Nguyên tắc chuẩn mực để Web Scraping tuân thủ kỹ thuật
Công nghệ chỉ là công cụ, tính ổn định nằm ở cách bạn kiểm soát hành vi của hệ thống. Để thu thập dữ liệu một cách minh bạch, bạn phải nắm rõ các ranh giới kỹ thuật sau:
Sự thật về file robots.txt: Bảng nội quy tự nguyện
Nhiều người vẫn nghĩ file https://domain.com/robots.txt là một lớp bảo mật không thể xuyên thủng. Thực tế, tài liệu từ Google Search Central khẳng định rõ: robots.txt không phải là một cơ chế bảo mật và các chỉ thị trong đó không thể ép buộc (cannot enforce) hành vi của crawler. Nó không có khả năng chặn đứng hệ thống nếu bạn chủ đích trích xuất thông tin.
Tuy nhiên, trong kiến trúc Thu thập dữ liệu chuẩn mực, tuân thủ robots.txt là một quy ước chuyên nghiệp. Mục đích chính của nó là giúp trang web quản lý lưu lượng, tránh bị quá tải. Nếu quản trị viên đã đặt Disallow: /api/private/, một kỹ sư sẽ chủ động viết rule cấu hình Scrapy bỏ qua đường dẫn này để tôn trọng tài nguyên mạng của họ.
Kiểm soát tần suất Request (Throttling) và User-Agent minh bạch
Hãy đặt độ trễ (sleep/idle time) từ 10 đến 20 giây giữa các request để mô phỏng hành vi thân thiện, không gây áp lực lên máy chủ đích.
Đồng thời, tuyệt đối không giả mạo trình duyệt bằng các chuỗi giả lập User-Agent. Hãy minh bạch danh tính của hệ thống, ví dụ: User-Agent: DataOps-MarketBot/1.0 (+https://yourcompany.com/bot; [email protected]). Khai báo rõ ràng giúp quản trị viên biết bạn là đối tác nghiên cứu thị trường, họ có thể liên hệ nhắc nhở nếu bot chạy lỗi thay vì chặn IP vĩnh viễn.
Tối ưu hóa bộ nhớ và lọc dữ liệu rác tại nguồn (Data Sanitization)
Một sai lầm phổ biến khi thiết kế hệ thống là tải toàn bộ mã nguồn HTML của trang web lên bộ nhớ RAM của VPS, sau đó mới dùng hàm Regex để lọc các trường dữ liệu cần thiết. Việc này gây lãng phí tài nguyên và dễ dẫn đến tình trạng tràn bộ nhớ (Memory Leak).
Giải pháp thực chiến: Bạn phải áp dụng tư duy tối ưu hóa ngay từ bước trích xuất.
- Chỉ nhắm mục tiêu (Targeting) vào các điểm cuối (endpoints) chứa dữ liệu cần thiết như giá cả, thông số sản phẩm.
- Tránh xa các khu vực yêu cầu đăng nhập (login).
- Ngay từ lúc viết XPath hoặc CSS Selectors trong Scrapy/Playwright, phải chủ động loại trừ (ignore) hoàn toàn các DOM elements (các block HTML) không chứa thông tin hữu ích. Việc ngăn chặn các payload dư thừa đi qua card mạng và vào RAM của VPS là cách hiệu quả nhất để đảm bảo hệ thống vận hành trơn tru và tiết kiệm băng thông.
Các bước thiết lập môi trường Scraping an toàn trên Ubuntu 24.04 LTS
Để triển khai hệ thống, bạn cần một hạ tầng hiện đại. Tính đến thời điểm hiện tại, Ubuntu 24.04 LTS là phiên bản Long Term Support tiêu chuẩn mới nhất.
Đặc biệt lưu ý, Ubuntu 24.04 LTS được cài đặt mặc định ngôn ngữ Python 3.12. Hệ điều hành và các công cụ cốt lõi phụ thuộc rất sâu vào phiên bản này. Tuyệt đối không được gỡ bỏ, hạ cấp (downgrade) hay thay đổi Python 3.12 mặc định của hệ thống vì nó sẽ làm crash toàn bộ VPS. Thay vào đó, chúng ta sẽ quản lý các dự án thu thập dữ liệu thông qua môi trường ảo (Virtual Environments).
Dưới đây là các lệnh Bash chuẩn mực để setup môi trường trên một VPS Ubuntu 24.04 mới toanh:
Cập nhật danh sách các gói phần mềm của hệ thống:
sudo apt update && sudo apt upgrade -yCài đặt Python mặc định (3.12+) cùng các công cụ quản lý package và môi trường ảo:
sudo apt install python3 python3-pip python3-venv -yTạo một thư mục riêng cho dự án và khởi tạo môi trường ảo hoàn toàn cô lập:
mkdir ~/market_scraper
cd ~/market_scraper
python3 -m venv venvKích hoạt môi trường ảo (Lúc này (venv) sẽ xuất hiện đầu dòng lệnh của bạn):
source venv/bin/activateBắt đầu cài đặt các thư viện trích xuất dữ liệu mạnh mẽ một cách an toàn:
pip install scrapy playwright beautifulsoup4 requests pandasVới Playwright, do công cụ này tải cả một nhân trình duyệt Chromium/Firefox về VPS để render nội dung động, hãy đảm bảo VPS của bạn có ít nhất 2GB RAM để quá trình thu thập dữ liệu không bị lỗi tràn bộ nhớ (Out-Of-Memory – OOM).
Lưu ý: Môi trường Python cô lập này không chỉ dùng để thu thập dữ liệu thị trường, bạn hoàn toàn có thể tái sử dụng nó cho các dự án tự động hóa khác, điển hình như việc Xây dựng công cụ Python SEO Audit tự động: Thay thế Screaming Frog với Rotating Proxy.
Câu hỏi thường gặp (FAQ)
1. Thu thập dữ liệu web có hợp lệ không?
Có, hoàn toàn hợp lệ nếu bạn chỉ thu thập dữ liệu công khai (Public Data) và tuân thủ Điều khoản dịch vụ (TOS) của website, đồng thời không gây ảnh hưởng đến hiệu suất hệ thống máy chủ đích.
2. Tải toàn bộ mã nguồn HTML lên RAM rồi mới lọc dữ liệu có phải là cách tối ưu?
Không. Việc kéo toàn bộ dữ liệu vào bộ nhớ tạm (RAM) dễ gây tràn bộ nhớ và lãng phí băng thông. Bạn buộc phải dùng Selector (XPath/CSS) để loại trừ triệt để các block HTML không cần thiết ngay từ khâu trích xuất.
3. Nên dùng Proxy Datacenter hay Proxy Residential để thu thập dữ liệu?
Dùng Proxy Datacenter (nhanh, chi phí hợp lý) cho các trang web công khai, hệ thống bảo mật cơ bản. Dùng Proxy Residential (độ tin cậy cao, chi phí cao hơn) cho các trang có WAF mạnh hoặc cần thu thập dữ liệu giá cả theo vị trí địa lý thực tế để không bị chặn.
4. Dùng VPN (Virtual Private Network) miễn phí thay cho Proxy được không?
Không hiệu quả. VPN đổi IP của toàn bộ VPS, làm tê liệt khả năng thu thập đa luồng (multi-threading). Hơn nữa, IP VPN miễn phí thường bị đưa vào danh sách đen. Hãy dùng Proxy Pool để xoay IP độc lập trên từng request.
5. Nên chọn cấu hình VPS bao nhiêu RAM là đủ để chạy hệ thống?
Tối thiểu 1 đến 2GB RAM nếu chỉ dùng các thư viện tải HTML thuần (Scrapy, BeautifulSoup). Cần 4GB RAM trở lên nếu thu thập trang web động cần render JavaScript (bằng Playwright/Selenium) để tránh lỗi tràn bộ nhớ (Out-Of-Memory).
6. Tại sao lại bị lỗi HTTP 429 Too Many Requests?
Do bạn gửi request quá nhanh, vi phạm giới hạn tỷ lệ (rate-limit) của máy chủ đích. Thay vì cố gửi tiếp, hãy cấu hình hệ thống đọc header Retry-After trong response để biết chính xác số giây cần chờ (sleep) trước khi thử lại.
7. Lỗi 403 Forbidden có giống với lỗi 429 không?
Hoàn toàn khác. 429 là do gửi quá nhanh (chỉ cần chờ). Còn 403 là do IP hoặc User-Agent của bạn đã bị hệ thống nhận diện và từ chối truy cập hoàn toàn (cần đổi sang IP Residential an toàn và cấu hình lại Header minh bạch).
Kết luận
Việc xây dựng hệ thống thu thập dữ liệu thị trường với VPS kết hợp Proxy không chỉ là bài toán giải quyết lỗi 429 hay vượt qua các lớp chặn IP. Nó phản ánh tư duy quản trị hạ tầng (DataOps) chuyên nghiệp của đội ngũ kỹ sư.
Bằng cách áp dụng Infrastructure as Code (Terraform và Ansible) để quản lý hàng loạt server, bảo vệ hệ thống với kiến trúc Zero Trust, xử lý lỗi thông minh dựa trên header HTTP, và đặc biệt là kỹ năng thiết lập Selectors tối ưu hóa bộ nhớ, hệ thống của bạn sẽ trở thành một cỗ máy dữ liệu tin cậy, ổn định và hiệu suất cao.
Đừng để những rào cản của máy tính cá nhân làm gián đoạn luồng dữ liệu của bạn. Hãy lên Cloud, thiết kế kiến trúc chuẩn mực, và biến dữ liệu công khai thành lợi thế cạnh tranh sắc bén nhất!
Tài liệu tham khảo