Tối ưu chi phí thuê VPS GPU chạy AI bằng vLLM & Docker: Tự host LLM/MoE chuẩn production
Tháng nào cũng vậy, nhìn bill API từ OpenAI hay Anthropic tăng phi mã tỉ lệ thuận với lượng user, chắc hẳn anh em developer nào cũng từng trải qua cảm giác xót ví. Khi ứng dụng bắt đầu scale, những vấn đề sát sườn như API bị rate-limit, nghẽn cổ chai (bottleneck) request, hay chi phí hạ tầng dội lên hàng nghìn đô la trở thành nỗi ám ảnh thường trực.
Lối thoát hiển nhiên là tự host các mô hình mã nguồn mở (Open-source LLMs), nhưng bài toán phần cứng lại khiến nhiều đội ngũ chùn bước: build một server vật lý tốn cả trăm triệu đồng, còn cấu hình hạ tầng Cloud không khéo lại liên tục dính lỗi OOM (Out of Memory) vì sập VRAM. Để hiểu rõ hơn về các lựa chọn hạ tầng ban đầu, bạn có thể tham khảo bài phân tích chuyên sâu so sánh ưu điểm của Cloud VPS và VPS vật lý thông thường.
Vậy làm sao để thiết lập một VPS GPU chạy AI vừa chịu tải tốt (high throughput), vừa không đốt sạch ngân sách dự án? Đặc biệt, có cách nào để xử lý được các mô hình tỷ tham số mới nhất của năm 2026 như DeepSeek-V4 hay GLM-5.1 trong một môi trường bị giới hạn tài nguyên mà không làm crash hệ thống? Hãy cùng đi sâu vào giải pháp kỹ thuật kết hợp vLLM, Docker và các chiến thuật tối ưu cấp độ production dưới đây.
Bài toán bức thiết của AI Engineer: Đốt tiền API hay chật vật tự host?
Trước khi bắt tay vào gõ lệnh deploy, chúng ta cần làm rõ bài toán tài chính: Liệu công sức bỏ ra để setup hạ tầng và maintain server có thực sự xứng đáng so với việc chỉ gọi API có sẵn?
Điểm hòa vốn (break-even): Khi nào tự host rẻ hơn API thương mại?
Nếu bạn chỉ đang làm PoC (Proof of Concept), việc gọi API trả phí vẫn là lựa chọn an toàn. Tuy nhiên, theo các số liệu thực tế, điểm hòa vốn (break-even) khi so sánh việc thuê server và dùng API thường rơi vào khoảng từ 6 triệu đến 42 triệu token/ngày.
- Mô hình lớn (Ví dụ: Llama 70B vs GPT-4o): Thuê một node H100 (SXM5) tốn khoảng 57,6 USD/ngày. Trong khi đó, API GPT-4o thu phí khoảng 10 USD/1M token output. Chỉ cần hệ thống của bạn vượt mốc ~5,76 triệu token/ngày, việc tự host bắt đầu sinh lời. Khi đạt thông lượng cao với vLLM, chi phí tự host trên H100 chỉ còn khoảng 1,67 USD/1M token (rẻ hơn 6 lần).
- Mô hình nhỏ (Ví dụ: 7B vs GPT-4o-mini): Thuê một card A100 80GB tốn khoảng 25,2 USD/ngày. So với mức giá siêu rẻ 0,60 USD/1M token của GPT-4o-mini, bạn cần xử lý khoảng 42 triệu token/ngày để hòa vốn. Ở mức thông lượng tối đa, chi phí tự host A100 rớt xuống mức đáy: 0,09 USD/1M token.
Đối với các startup có khối lượng công việc dưới 10 triệu token/tháng, việc đầu tư vào các dòng card GPU tiêu dùng mạnh mẽ như RTX 3090 hoặc 4090 giúp doanh nghiệp đạt điểm hòa vốn chỉ trong vòng 0,3 đến 3 tháng. Đặc biệt, nếu máy chủ của bạn được trang bị ổ cứng tốc độ cao, tốc độ load model weights sẽ nhanh hơn đáng kể. Bạn nên xem qua bài viết so sánh hiệu năng thực tế giữa VPS NVMe và VPS SSD để tối ưu khâu IO này.
Mẹo thực chiến: Kiến trúc lai (Hybrid Architecture)
Các con số trên giả định bạn bật GPU 24/7. Thực tế, bạn có thể cắt giảm 70% đến 80% ngân sách bằng cách:
- Dùng VPS CPU giá rẻ chạy Frontend 24/7.
- Dùng VPS GPU chạy AI dạng Spot Instance (máy chủ giao ngay) ở Backend. GPU chỉ khởi động khi có request thực sự và tự động ngủ khi rảnh rỗi.
Kiến trúc production & setup Docker tối ưu cho VPS GPU chạy AI
Việc SSH vào server, ném một file script Python lên và chạy bằng lệnh tmux chỉ dành cho môi trường dev. Để chạy thực chiến, bạn cần một pipeline tối ưu hóa toàn diện từ mạng, bộ nhớ đệm đến sức mạnh tính toán.
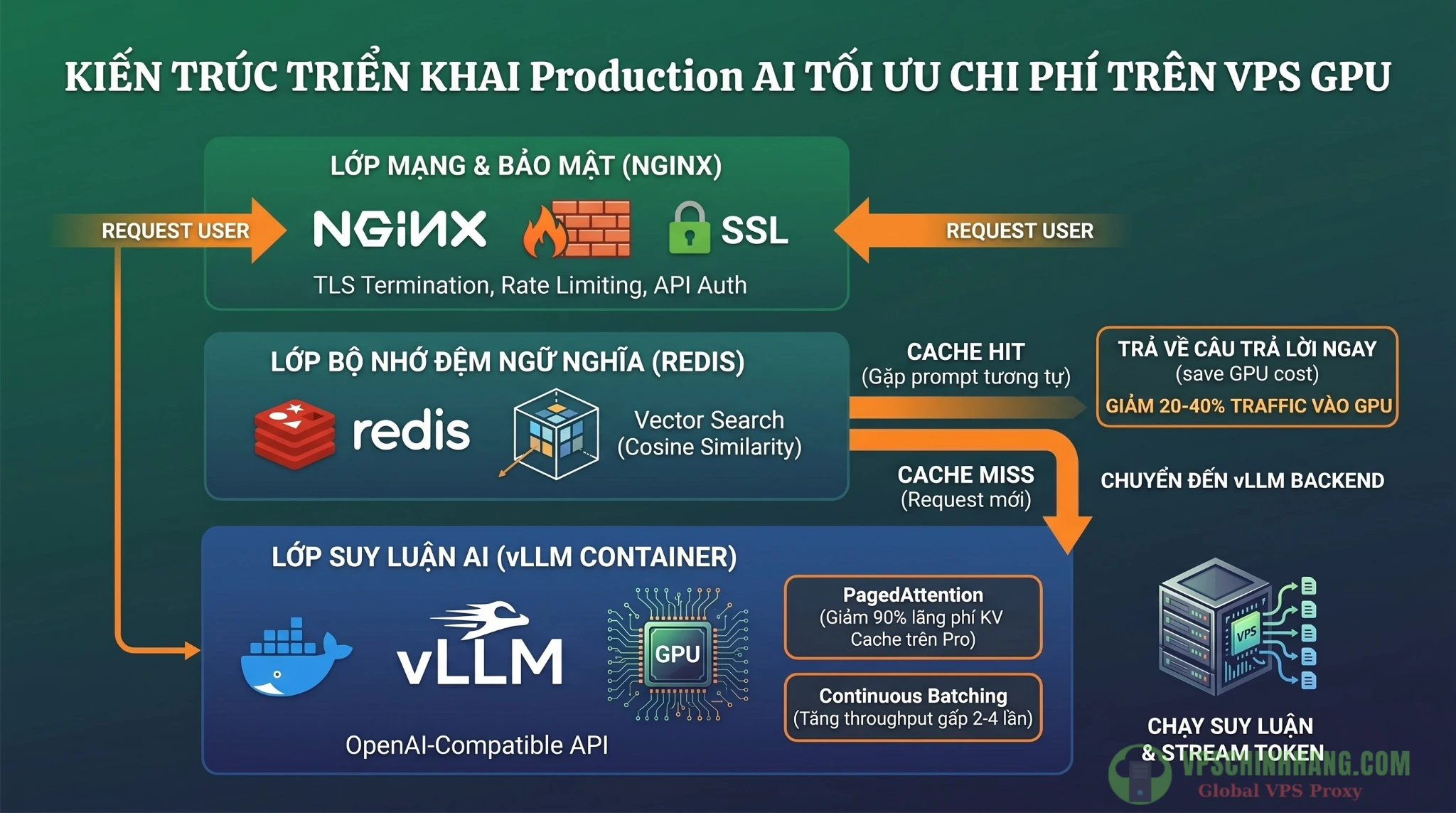
Kiến trúc lai tối ưu: Nginx bảo mật, Redis Vector Database chặn request trùng lặp (Cache Hit) để tiết kiệm GPU VRAM.
Luồng xử lý: Nginx -> Redis -> vLLM
- Lớp mạng (Nginx, Reverse Proxy): Phơi bày port 8000 của vLLM ra internet là tự sát. Nginx chịu trách nhiệm TLS/SSL, xác thực Bearer Token (VLLM_API_KEY) và định tuyến. Nếu bạn chạy nhiều model, Nginx sẽ dùng các block
location(/mistral/v1,/llama/v1) để trỏ luồng truy cập đến đúng tiến trình backend, tránh lỗi not found model.- Bạn có thể áp dụng kỹ thuật này tại hướng dẫn giới hạn Rate Limit trên Nginx để chặn đứng tấn công DDoS Layer 7 cho VPS.
- Lớp bộ nhớ đệm (Redis, Semantic Cache): Hoạt động như một Vector Database in-memory. Nó chặn các câu hỏi trùng lặp ý nghĩa ngay từ vòng ngoài để bảo vệ GPU.
- Lớp suy luận (vLLM, Inference Engine): Tiếp nhận request qua API tương thích chuẩn OpenAI, sinh token và đẩy ngược (stream) kết quả về qua Server-Sent Events (SSE).
Lệnh Docker quan trọng: Bắt buộc khai báo --ipc=host
Khi chạy vLLM qua Docker, một sai lầm phổ biến khiến container văng lỗi CUDA IPC ngay khi load model là quên cấp phát bộ nhớ chia sẻ (shared memory). Mặc định Docker chỉ cấp 64MB, một con số quá nhỏ bé.
vLLM sử dụng PyTorch multiprocessing để chia sẻ dữ liệu giữa các worker (đặc biệt khi chạy Tensor Parallelism trên nhiều GPU). Bạn BẮT BUỘC phải khai báo --ipc=host để vLLM dùng trực tiếp bộ nhớ chia sẻ của máy chủ, hoặc chỉ định --shm-size=1g (trở lên) nếu môi trường bảo mật không cho phép dùng chung không gian IPC.
Ép xung hiệu năng cho các mô hình lớn 2026 (DeepSeek-V4 & GLM-5.1)
Tháng 4/2026 chứng kiến sự thống trị của các siêu mô hình. Nhét chúng vào một VPS GPU là một bài toán toán học khắt khe.
Phân tích thông số & tính toán VRAM (lượng tử hóa FP8)
Lấy DeepSeek-V4-Flash làm ví dụ: Mô hình này có 284 tỷ tham số tổng (284B) và 13 tỷ tham số kích hoạt (13B active).
Nếu bạn dùng lượng tử hóa FP8 (1 tham số = 1 byte), phần Model Weights tĩnh sẽ ngốn chính xác 284 GB VRAM. Chưa dừng lại ở đó, bạn cần cộng thêm 10% đến 30% overhead để cấp phát cho KV Cache và activation buffers. Do đó, đừng mơ mộng chạy bản Flash trên 2 card RTX 3090. Bạn sẽ cần cụm multi-GPU cấp enterprise.
Đối với DeepSeek-V4-Pro (1.6T tổng, 49B active), quy mô còn khủng khiếp hơn rất nhiều.
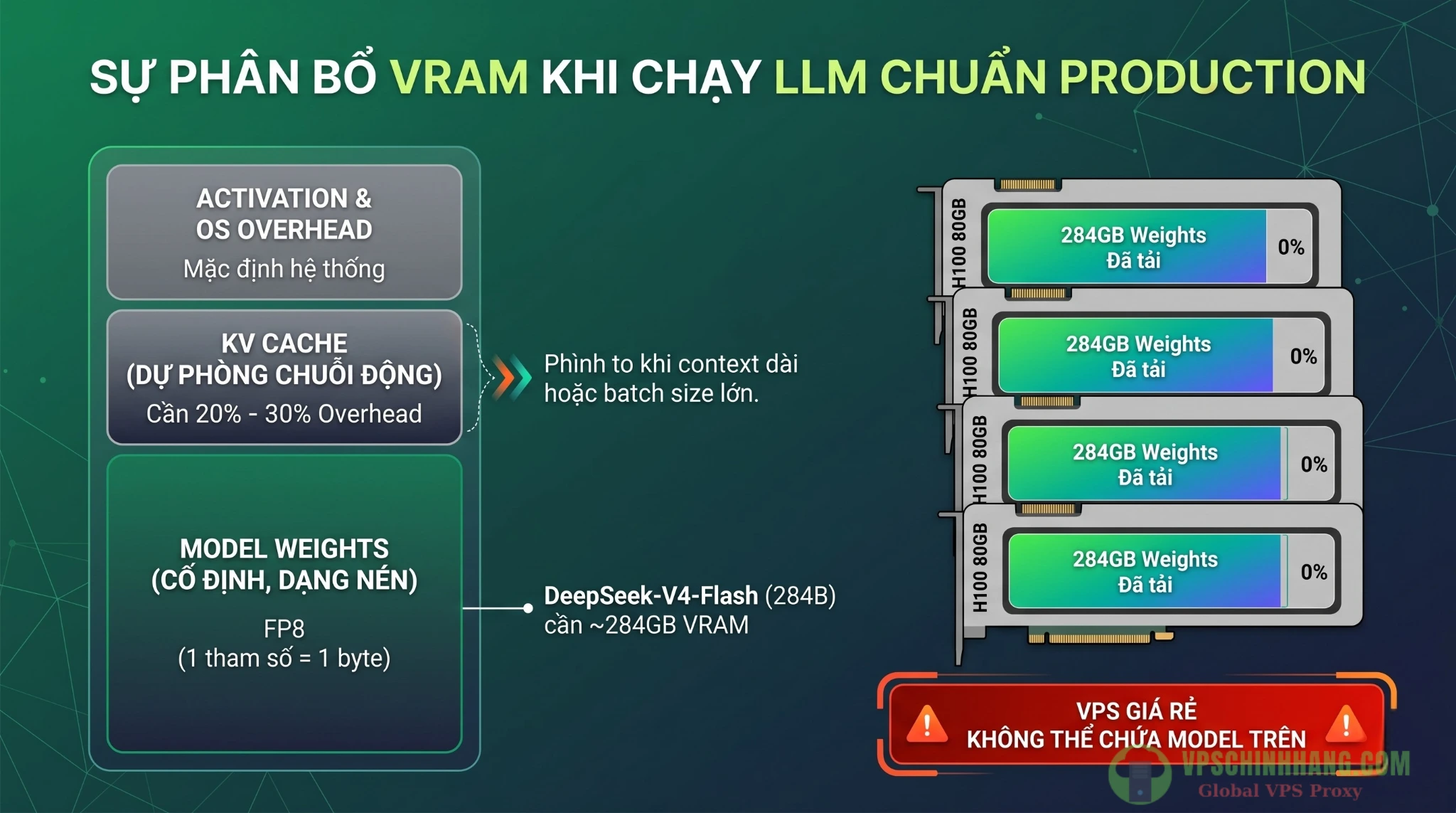
VRAM Math: 284B mô hình (như DeepSeek-V4-Flash) ở FP8 cần chính xác 284GB cho Weights, cần multi-GPU.
Đột phá KV Cache trên DeepSeek-V4-Pro
Điểm ăn tiền của dòng Pro là kiến trúc Hybrid Attention (kết hợp CSA/c4a và HCA/c128a) cùng DeepSeek Sparse Attention (DSA).
Nhờ kỹ thuật dùng chung vector Key/Value (kết hợp inverse RoPE) và nén sâu, ở thiết lập context 1 triệu token, DeepSeek-V4-Pro chỉ yêu cầu 10% dung lượng KV cache so với bản V3.2 tiền nhiệm (tức giảm 90% gánh nặng bộ nhớ). Ở BF16, 1 triệu token giờ chỉ tốn khoảng 9,62 GiB VRAM thay vì 83,9 GiB.
GLM-5.1: Flagship cho agentic engineering
Khác với DeepSeek, GLM-5.1 của Z.ai được thiết kế đo ni đóng giày cho Long-horizon tasks (tác vụ dài hạn). Mô hình này có thể hoạt động tự chủ và duy trì sự tập trung mục tiêu lên đến 8 giờ đồng hồ liên tục mà không bị mất phương hướng. Nó thực hiện vòng lặp Thử nghiệm, Phân tích, Tối ưu hóa (tự chạy code, đọc log, sửa lỗi) cực tốt, tích hợp hoàn hảo với các framework như Claude Code hay OpenClaw.
Để bảo vệ các mô hình quý giá này, hãy chắc chắn VPS của bạn đã được bảo mật theo hướng dẫn bảo mật VPS Linux toàn diện với 5 lớp phòng thủ.
4 kỹ thuật vLLM sống còn để không bị sập server (OOM)
Để hệ thống không sụp đổ khi traffic tăng vọt, bạn phải làm chủ các cơ chế cốt lõi của vLLM.
PagedAttention: Giải cứu VRAM khỏi phân mảnh
Lý do vLLM đạt thông lượng cao gấp 24 lần HuggingFace thuần là nhờ PagedAttention. Lấy cảm hứng từ virtual memory paging của hệ điều hành, nó chia KV Cache thành các khối (blocks) cố định, không liền kề. Bộ nhớ chỉ được cấp phát theo yêu cầu (on-demand) thông qua Block table. Cơ chế này loại bỏ phân mảnh ngoại vi, hạ mức lãng phí VRAM từ 80% xuống dưới 4%.

Cơ chế PagedAttention: vLLM chia nhỏ KV Cache thành các khối không liền kề, giúp giảm mức lãng phí bộ nhớ xuống dưới 4%.
--swap-space: Bảo hiểm chống tràn bộ nhớ
Mặc định vLLM cấp 4 GiB CPU RAM cho --swap-space. Khi GPU VRAM bị đầy bởi KV Cache của các request đang xử lý, thay vì báo lỗi OOM, vLLM sẽ tạm ngưng các request ưu tiên thấp. Nó đóng gói KV Cache của request đó và swap-out (chuyển) sang RAM của CPU. Khi GPU rảnh, nó sẽ swap-in kéo trở lại.
LƯU Ý CỰC KỲ QUAN TRỌNG: Cơ chế này CHỈ dùng để swap KV Cache, hoàn toàn KHÔNG có chức năng đẩy Model Weights hay Experts sang CPU.
Chunked prefill: Giải quyết nghẽn cổ chai prompt dài
Khi một user gửi file code 32K token, giai đoạn prefill (đọc hiểu) sẽ nuốt trọn năng lực tính toán, khiến các user đang chờ sinh token (decode) bị đứng hình (Head-of-Line Blocking).
Chunked prefill băm nhỏ prompt 32K đó ra thành các chunk. Scheduler của vLLM sẽ luân phiên (interleave) xử lý 1 chunk prefill, rồi lại xử lý 1 bước decode cho các user khác. Nhờ vậy, độ trễ sinh token (TBT) luôn mượt mà. Trên H100, kỹ thuật này giúp giảm P95 TTFT (độ trễ token đầu tiên) tới 68% cho các prompt dài.
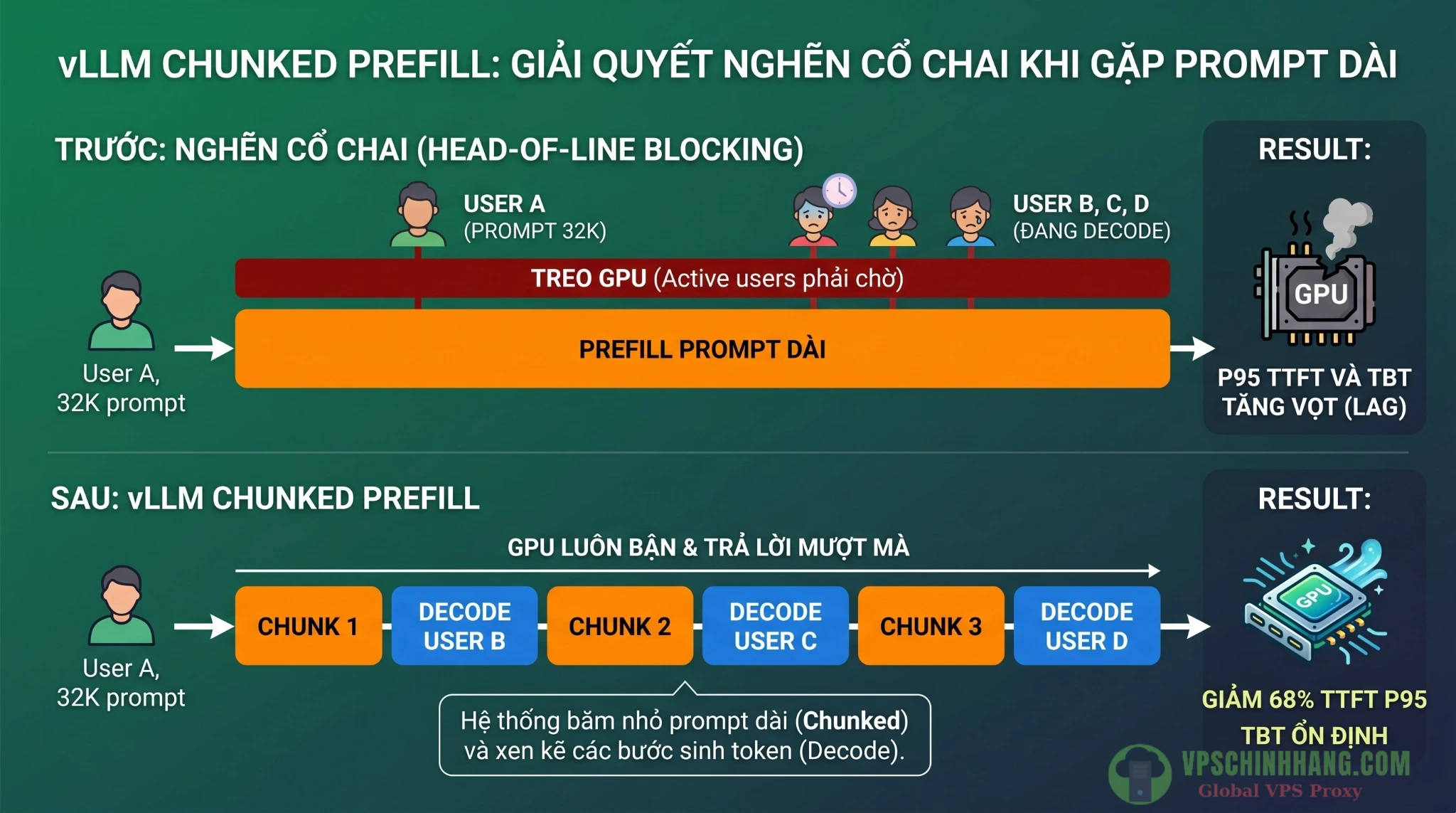
vLLM Chunked Prefill băm nhỏ các prompt dài (Prefill) và xen kẽ với các request sinh token (Decode), giúp ổn định độ trễ TBT của Active User.
--enable-prefix-caching: Zero recomputation
Nếu ứng dụng của bạn luôn đi kèm một System Prompt dài dằng dặc, hãy bật cờ này. vLLM sẽ tính toán tiền tố này một lần và lưu vật lý trên GPU. Các request sau từ nhiều user khác nhau sẽ dùng chung (tham chiếu) vào khối nhớ đó. Chi phí tính toán lại đoạn tiền tố bằng 0, giúp thông lượng tăng vọt từ 32% đến gấp 5 lần.
Xử lý multi-GPU & mở rộng: Khi nào nên dùng SGLang?
Tensor parallelism vs pipeline parallelism
Khi model 70B không nhét vừa 1 GPU:
- Tensor Parallelism (
-tp): Cắt ma trận trọng số ngay bên trong một layer. Rất nhanh, nhưng yêu cầu các GPU phải cắm chung một máy chủ và có cầu nối NVLink băng thông cực lớn. - Pipeline Parallelism (
-pp): Cắt model theo chiều dọc (GPU 1 chạy layer 1 đến 40, GPU 2 chạy 41 đến 80). Dùng khi bạn scale ra nhiều máy chủ (multi-node) hoặc GPU của bạn chạy qua chuẩn PCIe chậm chạp. (Công thức vàng: Đặt-tpbằng số GPU trên 1 node,-ppbằng số node hiện có).
SGLang và RadixAttention: Kẻ thách thức vLLM
vLLM tối ưu rất tốt, nhưng nếu bạn làm Agentic workflow, Tree-of-Thought, hay Chat Multi-turn, SGLang là một sự lựa chọn đôi khi còn tốt hơn.
SGLang sử dụng cấu trúc dữ liệu cây cơ số (RadixAttention) để tự động phát hiện và tái sử dụng KV Cache xuyên suốt các request mà không cần cấu hình thủ công. Tỷ lệ Cache Hit của SGLang đạt 85-95% cho Few-shot learning và 75-90% cho Multi-turn chat (vLLM chỉ loanh quanh 15-25%). Nhờ vậy, SGLang có thể đẩy thông lượng cao hơn 10% đến 20% trong các luồng Agent phức tạp.
Tuyệt chiêu giảm chi phí hạ tầng cùng Redis & auto-stop
Semantic caching với Redis Vector Database
Thay vì khớp text 100%, Semantic Cache dùng embedding model biến câu hỏi thành vector. Redis sẽ đo khoảng cách góc giữa 2 vector bằng công thức Cosine Similarity:
$d(u, v) = 1 – \frac{u \cdot v}{||u|| ||v||}$
Bằng tính năng Range Queries (lọc theo bán kính radius), nếu câu hỏi mới có góc Cosine đủ nhỏ so với câu hỏi cũ trong Redis, nó sẽ tạo ra Cache Hit. Kết quả được trả về ngay lập tức từ RAM, bỏ qua hoàn toàn việc gọi GPU, bảo vệ ngân sách tính toán của bạn.
Auto-stop script cho Spot Instance
Thuê Spot Instance mà để máy chạy không (idle) qua đêm là lãng phí tài nguyên. Hãy viết một cron job ping vào endpoint Prometheus của vLLM (/metrics).
Bạn cần kiểm tra đồng thời 2 metric Gauge: vllm:num_requests_running (số chuỗi đang decode) và vllm:num_requests_waiting (số chuỗi đang xếp hàng chờ). Chỉ khi CẢ HAI metric này = 0 liên tục trong 30 phút, script mới gọi API của provider (như Vast.ai) để destroy hoặc pause máy chủ.
Bạn có thể tham khảo cách thiết lập dashboard giám sát tại bài viết hướng dẫn giám sát băng thông VPS bằng Prometheus và Grafana để xử lý nghẽn cổ chai.
Câu hỏi thường gặp (FAQ)
Bài toán chi phí & hạ tầng
1. Điểm hòa vốn khi tự host LLM trên VPS GPU vs dùng API trả phí?
Khoảng 6 – 42 triệu token/ngày tùy model. Vượt mốc này, tự host rẻ hơn API tới 80%. Với startup dùng model <30B trên RTX 3090, chỉ mất 0.3 đến 3 tháng để hoàn vốn hạ tầng.
2. PagedAttention của vLLM là gì?
Thuật toán quản lý bộ nhớ ảo cho KV Cache. Giúp giảm lãng phí VRAM xuống dưới 4% và tăng thông lượng (throughput) gấp 2 đến 4 lần so với Transformers thuần.
3. Tại sao phải kết hợp Nginx, Redis và vLLM?
Nginx lo bảo mật và chặn DDoS; Redis chặn câu hỏi trùng lặp (Cache Hit); vLLM dồn 100% tài nguyên GPU để sinh token mới.
4. Tại sao chạy Docker vLLM bắt buộc cần cờ --ipc=host?
Để vLLM dùng chung bộ nhớ chia sẻ vật lý của máy chủ, tránh lỗi văng app (CUDA IPC) do Docker mặc định chỉ cấp tối đa 64MB RAM.
Sức mạnh của DeepSeek-V4 & GLM-5.1
1. Cấu hình phần cứng của DeepSeek-V4 Pro và Flash?
- Bản Pro: 1.6T tổng tham số (kích hoạt 49B).
- Bản Flash: 284B tổng tham số (kích hoạt 13B).
2. DeepSeek-V4-Pro nén KV Cache khủng mức nào?
Ở độ dài 1 triệu token, bản Pro chỉ tốn 10% VRAM cho KV Cache (giảm 90% gánh nặng bộ nhớ) so với bản V3.2 nhờ Hybrid Attention.
3. Mô hình GLM-5.1 tối ưu đặc biệt cho việc gì?
Tối ưu riêng cho Agentic Engineering và tác vụ tự chủ dài hạn (chạy liên tục 8 tiếng, tự code, tự debug).
4. Model 284B (như DeepSeek Flash) chạy FP8 ngốn bao nhiêu VRAM?
Chính xác 284GB VRAM cho riêng phần Model Weights (trọng số), chưa tính thêm 10% đến 30% VRAM dự phòng cho KV Cache.
Tối ưu tham số vLLM & Multi-GPU
1. Tham số --swap-space trong vLLM đẩy cái gì sang CPU?
Chỉ đẩy KV Cache từ GPU sang RAM máy chủ khi bị quá tải. TUYỆT ĐỐI KHÔNG dùng để swap trọng số mô hình (Weights/Experts).
2. Chunked Prefill giải quyết vấn đề gì?
Băm nhỏ prompt siêu dài thành nhiều phần để xử lý xen kẽ với các request sinh token khác, giúp GPU không bị treo cứng (Head-of-Line Blocking).
3. Tác dụng của --enable-prefix-caching?
Tính toán System Prompt/Tài liệu 1 lần và share bộ nhớ cho mọi user. Đưa chi phí tính toán lại tiền tố về 0, tăng thông lượng mạnh mẽ.
4. Model to hơn VRAM 1 GPU thì làm sao?
Dùng Tensor Parallelism (--tensor-parallel-size). Nó cắt ma trận trọng số ra chạy song song trên nhiều GPU trong cùng 1 máy chủ (yêu cầu có cầu nối NVLink).
Mở rộng & tối ưu chi phí
1. Khi nào SGLang tốt hơn vLLM?
Khi làm Multi-Agent hoặc Tree-of-Thought. Cấu trúc RadixAttention của SGLang tự động share KV Cache cực tốt cho các đoạn hội thoại nhiều bước (Cache hit >85%).
2. Semantic Cache (Redis) chặn gọi GPU bằng cách nào?
Nhúng câu hỏi thành vector. Dùng Cosine Similarity đo khoảng cách góc, nếu giống câu hỏi cũ >95% -> Nhả luôn kết quả từ Redis, tiết kiệm 100% GPU.
3. Metric nào trên Prometheus dùng để viết Auto-stop script?
Check đồng thời 2 metric: vllm:num_requests_running và vllm:num_requests_waiting. Cả 2 bằng 0 liên tục thì tự động tắt máy chủ để tiết kiệm chi phí.
Kết luận
Vận hành một VPS GPU chạy AI hiệu năng cao là sự kết hợp khéo léo giữa kiến trúc phần mềm, toán học VRAM và hiểu biết sâu sắc về vòng đời của token.
Checklist trước khi đưa LLM lên Production:
- Đã tính toán chuẩn VRAM (Weights + Overhead KV Cache)?
- Container Docker đã được cấp
--ipc=host? - Đã kích hoạt
Chunked Prefillvà--enable-prefix-cachingcho prompt dài? - Có kịch bản Multi-GPU (
-tp/-pp) phù hợp với băng thông NVLink/PCIe chưa? - Đã cấu hình Redis Semantic Cache chặn request trùng lặp ý nghĩa?
- Đã thiết lập Auto-stop script giám sát
num_requests_runningvàwaiting?
Tài liệu tham khảo