


Giám sát băng thông VPS bằng Prometheus & Grafana: Dẹp loạn nghẽn cổ chai
Hệ thống đang chạy chiến dịch, API gateway bất ngờ trả về hàng loạt lỗi 502 Bad Gateway và request bị timeout. Theo phản xạ, bạn SSH vào server, gõ htop và thấy CPU vẫn hoạt động ổn định ở mức 20%, RAM dư dả, Disk I/O hoàn toàn tĩnh lặng. Mọi tài nguyên tính toán đều ổn định, ứng dụng không hề crash, nhưng user thì liên tục kêu ca vì rớt kết nối. Vấn đề rốt cuộc nằm ở đâu?
Câu trả lời thường nằm ở vùng tối mà giới DevOps rất dễ bỏ qua: Nút thắt cổ chai mạng (Network Bottleneck). Hệ thống không thiếu sức mạnh tính toán, mà nó đang bị nghẹt thở vì giới hạn PPS (Packets Per Second) đã kịch trần, hoặc hàng đợi TCP đang vứt bỏ gói tin liên tục. Việc xây dựng một hệ thống giám sát băng thông VPS theo thời gian thực không chỉ là tùy chọn có thì tốt, mà là yếu tố sống còn để định vị lỗi. Bạn đã sẵn sàng nhìn thấu từng bit dữ liệu chảy qua server và thiết lập báo động trước khi thảm họa xảy ra chưa? Cùng chẩn đoán hệ thống ngay bây giờ nhé?
Nút thắt mạng (Network Bottleneck): Nỗi ám ảnh vô hình của SysAdmin
Nhiều người quản trị bị đánh lừa bởi cam kết thông lượng 1Gbps hay 10Gbps từ nhà cung cấp, mà quên mất rằng hiệu năng thực tế bị chi phối bởi kiến trúc hạ tầng (nếu bạn chưa rõ sự khác biệt này, hãy tìm hiểu thêm về khái niệm Cloud VPS cũng như so sánh ưu điểm của Cloud VPS và VPS vật lý thông thường). Cụ thể, tốc độ mạng thực tế chịu ảnh hưởng bởi 3 yếu tố cốt lõi trong hạ tầng ảo hóa:
- Sự chia sẻ cổng vật lý (Shared Port): Card mạng ảo (vNIC) của bạn đang phải dùng chung cổng vật lý với hàng tá các máy ảo khác trên cùng một hypervisor. Nếu họ vắt kiệt băng thông vật lý, tốc độ của bạn sẽ suy giảm trực tiếp.
- Giới hạn Packets Per Second (PPS): Băng thông (Mbps) có thể chưa đầy, nhưng nếu có hàng triệu request API nhỏ giọt ập tới, số lượng ngắt mạng (interrupts) sẽ tăng vọt. Nếu CPU không được cấp đủ ngân sách (netdev_budget) để chạy các tiến trình ngắt mềm (SoftIRQs), gói tin sẽ bị rớt ngay từ vòng gửi xe.
- Hiện tượng tràn bộ đệm (Buffer Overflow): Khi có traffic spike (lưu lượng bùng nổ), tốc độ gói tin bay tới vượt quá khả năng xử lý của kernel. Nút thắt thường xảy ra tại RX Ring Buffer (bộ đệm của card mạng) hoặc
net.core.netdev_max_backlog(hàng đợi lớp L2/L3 của OS). Thậm chí, nếu bộ đệm cấu hình quá sâu, bạn sẽ gặp hiện tượng Bufferbloat, tình trạng gói tin không bị drop nhưng bị kẹt trong hàng đợi hàng giây đồng hồ, đẩy độ trễ (latency) lên cực đại.
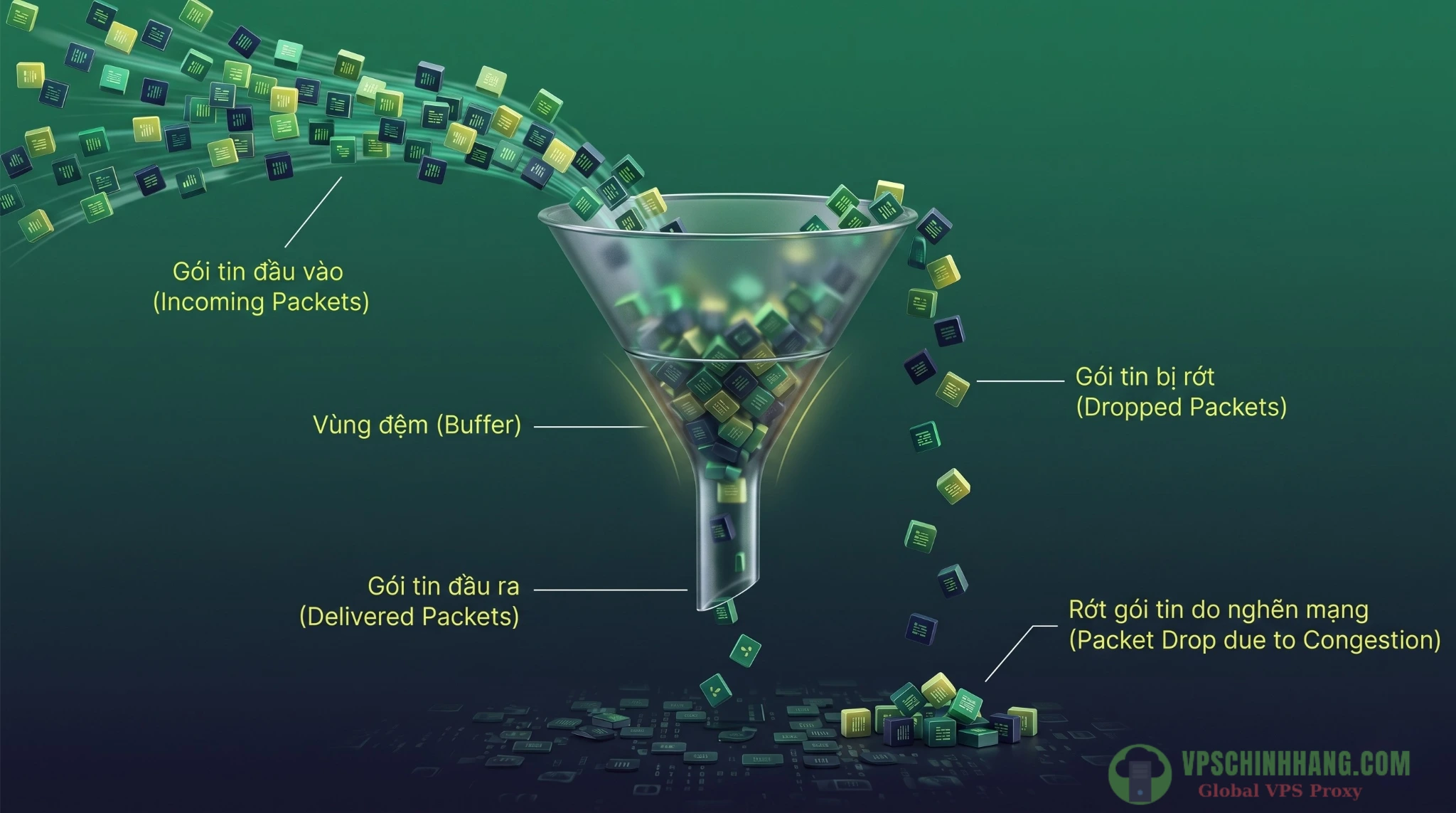
Mô phỏng hiện tượng tràn hàng đợi (Buffer Overflow) khi số lượng gói tin (PPS) đổ về vượt quá sức chứa của card mạng.
Kiến trúc giám sát: Tại sao Prometheus + Grafana lại là lựa chọn tối ưu?
Thay vì dùng các hệ thống giám sát cũ, Stack Prometheus + Grafana giải quyết được các bài toán đặc thù của hạ tầng mạng nhờ 2 vũ khí hạng nặng:
Sức mạnh của cơ chế Pull (chủ động thu thập dữ liệu)
Với cơ chế Push (đẩy data), nếu rớt mạng, bạn sẽ mất trắng dữ liệu và mất khả năng quan sát ngay tại thời điểm quan trọng nhất. Ngược lại, cơ chế Pull của Prometheus yêu cầu client chỉ duy trì một bộ đếm (counter) liên tục tăng dần. Khi mạng chập chờn khiến một lần thu thập dữ liệu thất bại, Prometheus không hề làm mất tổng lượng dữ liệu, mà sẽ dùng hàm rate() nội suy chính xác tốc độ gia tăng khi kết nối phục hồi. Ngoài ra, cơ chế này giúp nhận diện cực nhạy sự cố Target Down và tự động xử lý mượt mà khi bộ đếm bị reset (do sập node/khởi động lại).
Time-series Database (TSDB) sinh ra cho Networking
Nếu dùng RDBMS (như MySQL), việc ghi nhận hàng ngàn metric mạng mỗi giây sẽ gây nghẽn I/O (Bottleneck Ingestion). TSDB của Prometheus không chỉ tối ưu ghi chép qua bộ nhớ và WAL, mà còn cung cấp sẵn các mô hình dữ liệu đa chiều (Labels). Các hàm toán học chuyên dụng như rate() xử lý đặc thù của mạng cực tốt, tự bù trừ khi counter bị reset thay vì trả về kết quả băng thông âm như SQL truyền thống.
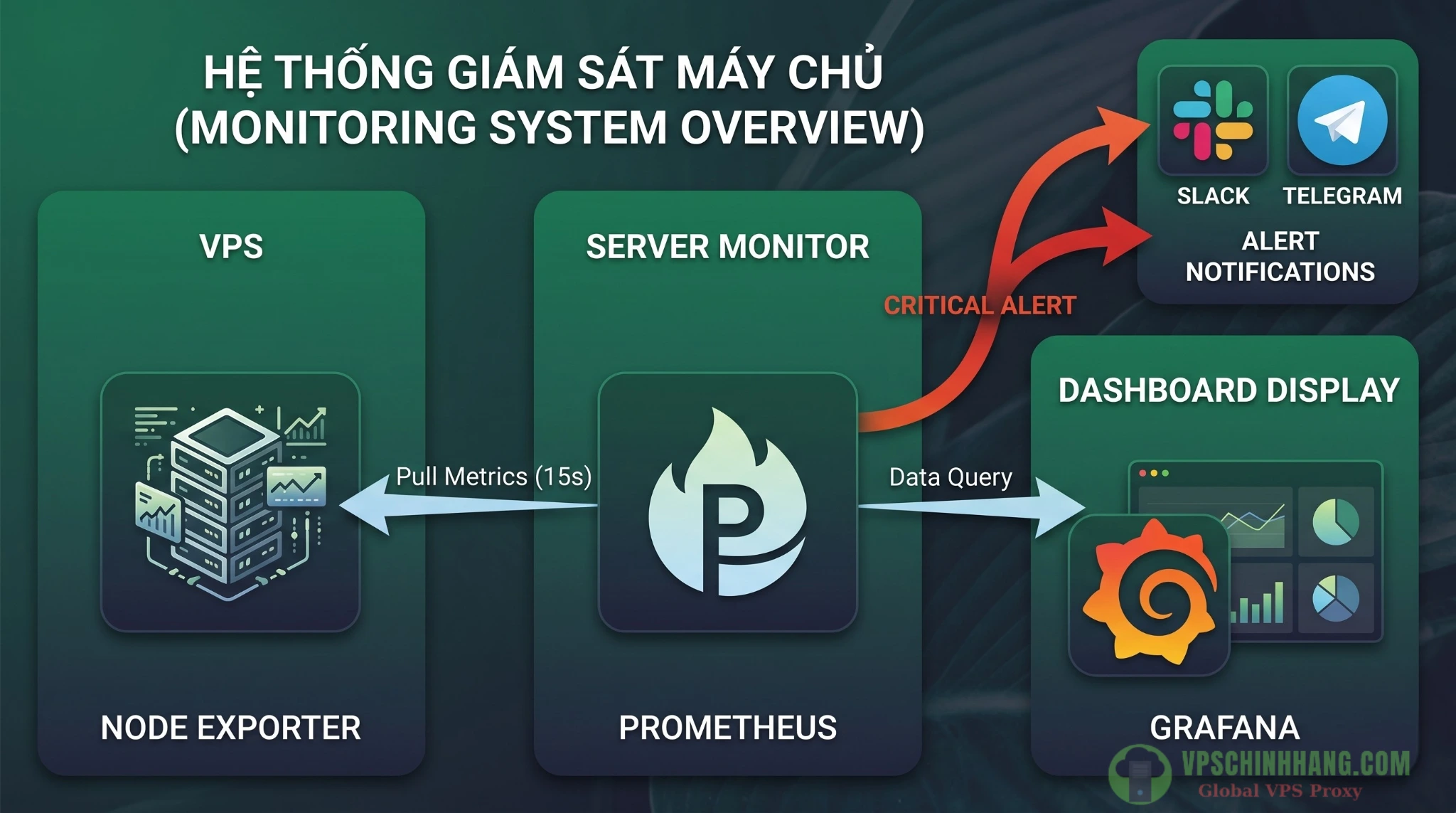
Luồng dữ liệu chuẩn SRE: Node Exporter hứng metrics tại VPS -> Prometheus chủ động thu thập dữ liệu định kỳ -> Grafana trực quan hóa thành biểu đồ.
Thực chiến setup hệ thống giám sát băng thông VPS
Bước 1: Deploy Node Exporter (tải tự động & bảo mật cực đoan)
Thay vì fix cứng một version dễ bị lỗi thời, hãy dùng Script sau để gọi Github API, dùng jq dò tìm chuẩn xác và tải về bản Node Exporter mới nhất cho kiến trúc amd64:
curl -s https://api.github.com/repos/prometheus/node_exporter/releases/latest \
| jq -r '.assets[] | select(.name | test(".*linux-amd64.tar.gz")).browser_download_url' \
| wget -qi -CẢNH BÁO BẢO MẬT:
Tuyệt đối không phơi port 9100 ra Internet. Các endpoint của Node Exporter chứa cực kỳ nhiều Label nhạy cảm (SSH keys, credentials từ biến môi trường). Tệ hơn, hacker có thể nhắm vào endpoint /debug/pprof để gây cạn kiệt tài nguyên CPU/RAM (Tấn công DoS).
- Giải pháp: Hãy chạy Node Exporter qua mạng riêng ảo WireGuard (chỉ lắng nghe trên interface
wg0). Để thiết lập đường hầm bảo mật này, bạn nên tham khảo thêm bài đánh giá chi tiết giữa Tailscale và WireGuard để tìm ra giải pháp VPN quản trị VPS từ xa tối ưu nhất (2026). Nếu không có VPN, hãy dùngiptableshoặcUFWđể whitelist duy nhất IP của máy chủ Prometheus.
Bước 2: Config Prometheus (tại sao lại là 15 giây?)
Trong prometheus.yml, hãy set scrape_interval: 15s.
Đây là mức lý tưởng cho hạ tầng mạng. Nếu ép xuống 5s, dung lượng lưu trữ sẽ phình to gấp 4 lần và làm chậm các truy vấn biểu đồ. Ngược lại, mức 15s cung cấp đủ độ mịn để hiển thị độ trễ cảnh báo (alert latency) chỉ trong 1-2 phút.
Bước 3: Build Dashboard Grafana
Đăng nhập Grafana, vào mục Import và gõ ID 1860 (Node Exporter Full). Bạn sẽ có ngay một mặt tiền trực quan, phần việc còn lại là tùy chỉnh các PromQL queries để chẩn đoán hệ thống.
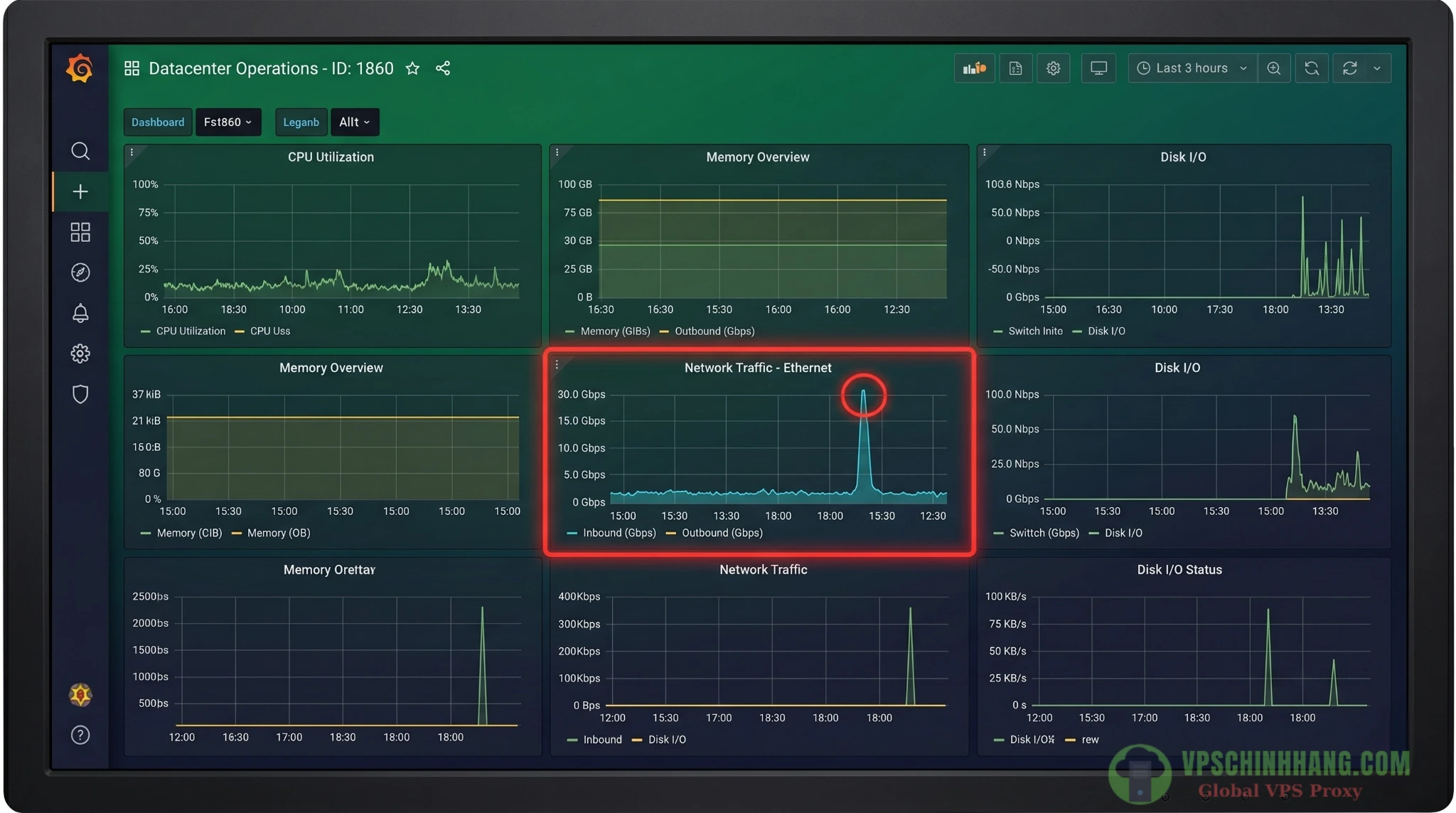
Giao diện Grafana Dashboard (ID 1860) giúp SysAdmin dễ dàng phát hiện các đợt bùng nổ traffic (Spikes) chỉ trong nháy mắt.
Phân tích mạng VPS: Các PromQL queries chẩn đoán cực bén
Việc chẩn đoán yêu cầu SysAdmin phải phân tách rạch ròi 2 tầng mạng:
- Nhóm
node_network_(Giao diện vật lý L1/L2): Gắn với từng thiết bị (nhưeth0). Dùng để đo băng thông (bps) và phát hiện rớt gói tin do quá tải phần cứng. - Nhóm
node_netstat_(Kernel Networking L3/L4): Thống kê tổng thể mạng con của OS. Dùng để xem TCP Connections (node_netstat_Tcp_CurrEstab), cạn kiệt port, hoặc tràn hàng đợi do OS xử lý không kịp.- Nếu biểu đồ vọt lên vài vạn kết nối, ứng dụng của bạn có thể đang bị tấn công DDoS HTTP Flood. Ngay lúc này, bạn cần giới hạn Rate Limit trên Nginx để chặn đứng tấn công DDoS Layer 7 cho VPS nhằm bảo vệ hệ thống, hoặc kiểm tra lại cơ chế Connection Pooling của database.
Quy tắc 4x của chuyên gia cho hàm rate()
Theo Brian Brazil (nhà sáng lập Robust Perception), time window truyền vào hàm rate() phải lớn gấp ít nhất 4 lần chu kỳ scrape.
Với scrape_interval là 15s, ta buộc phải dùng [1m]. Tại sao không dùng [5m] cho mượt? Bởi vì hàm rate() có tính trung bình hóa (averaging effect). Nếu dùng [5m], bạn sẽ làm phẳng (smooth out) toàn bộ các đợt bùng nổ băng thông (micro-bursts) diễn ra trong vài giây, dẫn đến việc nhìn thấy biểu đồ bình thường nhưng user thì rớt mạng liên tục.
Tính tốc độ Inbound (Mbps) loại trừ interface ảo
(Nhân 8 đổi sang bits, chia 1e6 đổi sang Megabits. Loại bỏ localhost và các container interfaces).
rate(node_network_receive_bytes_total{device!~"lo|docker.*|veth.*"}[1m]) * 8 / 1e6Tính % Utilization (kịch trần băng thông)
(Bí quyết: Cú pháp and ... > 0 là guard bắt buộc để tránh lỗi chia cho 0 gây hỏng biểu đồ khi Node Exporter không đọc được tốc độ của vNIC).
(
rate(node_network_receive_bytes_total{device!~"lo|docker.*"}[1m])
/
node_network_speed_bytes{device!~"lo|docker.*"}
) * 100
and (node_network_speed_bytes{device!~"lo|docker.*"} > 0)Thiết lập Alert Rules: Tư duy chuẩn SRE (Site Reliability Engineering)
Theo triết lý SRE: Chỉ cảnh báo dựa trên Triệu chứng (Symptoms), không cảnh báo Nguyên nhân (Causes).
- Nguyên nhân (Cảnh báo Warning): Băng thông đạt 80% không có nghĩa là hệ thống lỗi. Nếu đặt Critical, bạn sẽ bị spam cảnh báo rác (alert fatigue). Mức này chỉ nên gửi tin nhắn vào Slack để phục vụ việc Quy hoạch năng lực (Capacity Planning).
- Triệu chứng (Cảnh báo Critical): Rớt gói tin (Packet drop) > 1% hoặc Interface Down ảnh hưởng trực tiếp đến trải nghiệm người dùng. Những Alert này xứng đáng để đánh thức kỹ sư trực hệ thống lúc 2h sáng.
Bắt được bệnh rồi thì làm gì? (Troubleshoot & Tuning Kernel)
Khi Dashboard đỏ rực vì rớt gói tin, hãy kết hợp Grafana (phát hiện thời điểm When) và CLI (phát hiện vị trí Where).
Phân biệt lỗi phần cứng (NIC) và lỗi hệ điều hành
- Lỗi phần cứng: Gõ lệnh
ethtool -S eth0 | grep -i drop. Nếu thấy các counter nhưrx_droppedhoặcrx_fifo_errorstăng, RX Ring Buffer của card mạng đã bị lấp đầy. Bạn cần dùngethtool -Gđể tăng kích thước vòng đệm. - Lỗi hệ điều hành: Gõ
cat /proc/net/softnet_stat(Đọc dưới dạng Hex).- Nếu cột 2 tăng: Hardware đã nhận tốt, nhưng hàng đợi OS (
netdev_max_backlog) bị đầy. - Nếu cột 3 tăng: Hệ điều hành bị nghẽn cổ chai CPU (cạn kiệt
netdev_budgetcho SoftIRQ). Cần dùngirqbalanceđể tản tải ra các Core khác.
- Nếu cột 2 tăng: Hardware đã nhận tốt, nhưng hàng đợi OS (
Xử lý TX Drops (rớt mạng chiều gửi đi)
Đừng đánh đồng 2 chiều Inbound/Outbound. Hãy gõ ip -s link. Nếu thấy cột dropped ở phần TX tăng, hệ thống đang bị tràn hàng đợi truyền tải do Burst Writes.
- Cách fix: Tăng gấp đôi chiều dài hàng đợi truyền bằng lệnh
ip link set dev eth0 txqueuelen 2000.
Tối ưu hóa bằng Sysctl
- Tăng
net.core.netdev_max_backlog: Dùng cho hạ tầng 10Gbps+ hoặc khi hệ thống chịu PPS cực lớn (cột 2 củasoftnet_stattăng). - Nới lỏng TCP Window Size (
tcp_rmem/tcp_wmem): Dùng khi đường truyền có Băng thông lớn và Độ trễ cao (High BDP). Cực kỳ hữu dụng cho các luồng tải file lớn (Elephant flows) để tránh hiện tượng cắt bỏ gói tin (TCP Pruning).
Giải pháp đột phá TCP BBR của Google
Thay vì dùng thuật toán CUBIC (chống nghẽn dựa trên rớt gói tin, hay Loss-based) luôn gây ra hiện tượng Bufferbloat và bóp băng thông oan uổng khi có rớt gói ngẫu nhiên, hãy kích hoạt TCP BBR (Dựa trên mô hình băng thông và độ trễ).
BBR chủ động đo lường RTT và giữ cho bộ đệm luôn ở mức ngắn nhất. Trong các môi trường mạng xa (như từ Mỹ về VN) có packet loss 1%, BBR cho thông lượng (throughput) cao gấp 2700 lần so với CUBIC.
net.core.default_qdisc = fq
net.ipv4.tcp_congestion_control = bbr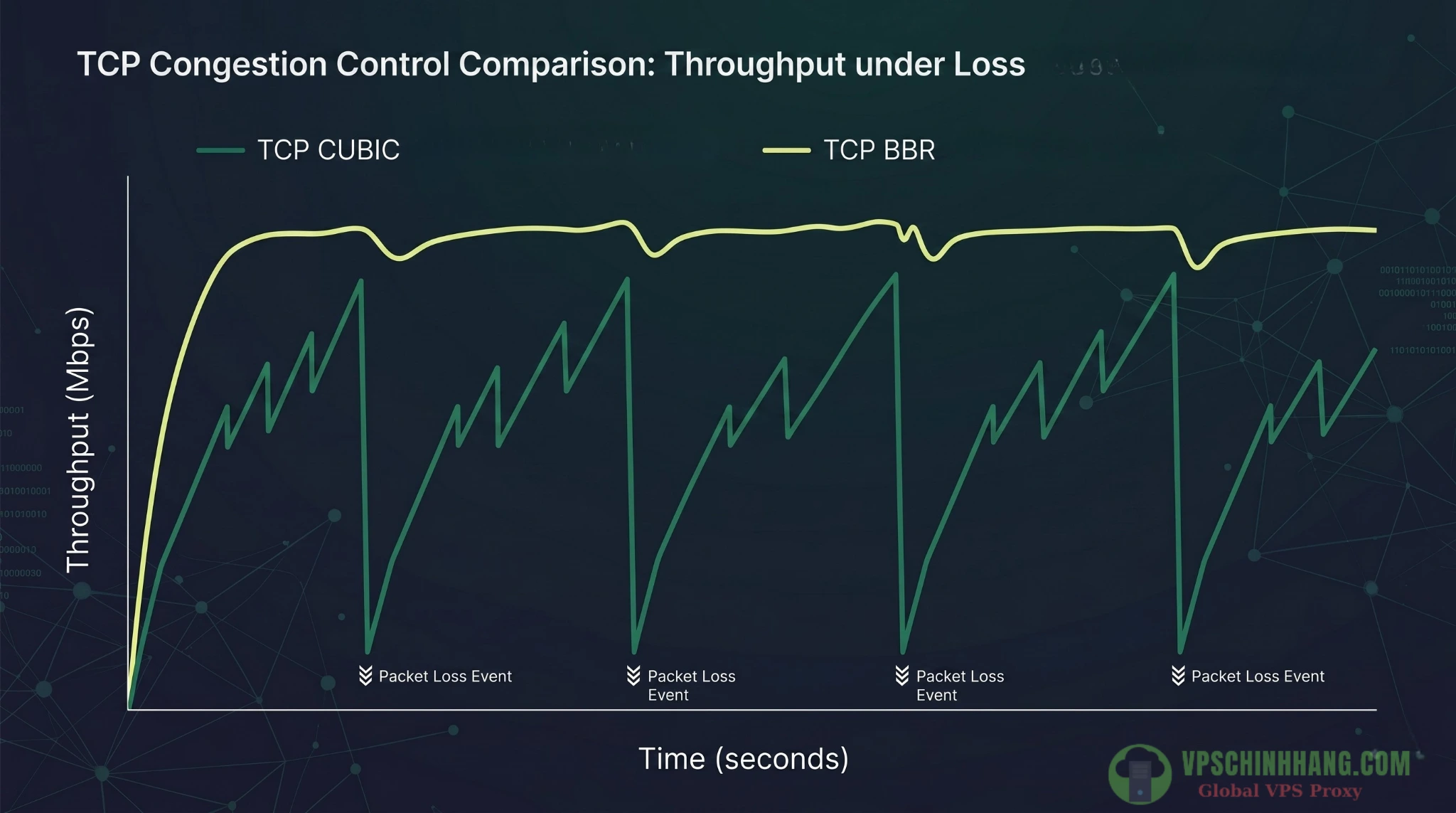
TCP BBR duy trì luồng truyền tải mượt mà dựa trên độ trễ, khắc phục triệt để nhược điểm Bufferbloat và rớt thông lượng của thuật toán CUBIC.
Câu hỏi thường gặp (FAQ)
1. Tại sao VPS báo CPU/RAM thấp nhưng mạng vẫn chậm, request bị timeout?
Nút thắt nằm ở hạ tầng mạng (Network Bottleneck). Hệ thống đang vướng giới hạn gói tin trên giây (PPS), card mạng bị tràn bộ đệm (Buffer Overflow) do traffic spike, hoặc băng thông vật lý đã bị vắt kiệt do phải chia sẻ (shared port) với các VPS khác trên cùng một máy chủ.
2. Chạy Node Exporter và Prometheus có làm quá tải VPS, ngốn CPU/RAM không?
Node Exporter thì không, nhưng Prometheus thì có. Node Exporter siêu nhẹ (<20MB RAM, ~0% CPU), chạy thoải mái trên VPS 512MB. Ngược lại, Prometheus Server (chứa TSDB) rất tốn RAM/Disk. Bắt buộc phải cài Prometheus/Grafana trên một máy chủ giám sát độc lập, tuyệt đối không cài chung với VPS đang chạy App Production.
3. Hàm rate() trong Prometheus nên đặt time window là bao nhiêu?
Áp dụng quy tắc 4x: Time window phải lớn gấp 4 lần chu kỳ lấy mẫu (scrape_interval). Nếu bạn lấy mẫu mỗi 15s, bạn bắt buộc dùng [1m]. Không dùng [5m] để đo mạng vì tính trung bình hóa của nó sẽ làm phẳng biểu đồ, khiến bạn không nhìn thấy các đợt nghẽn mạng chớp nhoáng (micro-bursts).
4. Tại sao biểu đồ băng thông trên Grafana thỉnh thoảng bị đứt đoạn (Gaps) hoặc báo No Data?
Do rớt mạng hoặc sập Node. Prometheus không thể kéo dữ liệu đúng chu kỳ (Scrape Timeout) vì đường truyền chập chờn, hoặc Node Exporter đã bị hệ điều hành tắt ép (OOM Kill). Gõ ngay lệnh up == 0 vào PromQL để xác định xem VPS nào đang sập.
5. Dữ liệu lưu trong Prometheus cứ phình to liên tục, làm sao để tránh bị đầy ổ cứng (Disk Full)?
Đặt trần dung lượng lưu trữ. Mở file cấu hình service của Prometheus và thêm cờ --storage.tsdb.retention.size=10GB (hoặc theo số ngày --storage.tsdb.retention.time=15d). Prometheus sẽ tự động xóa data cũ nhất khi chạm ngưỡng này.
6. Giám sát cùng lúc hàng chục VPS ở nhiều nhà cung cấp (VN, US, EU) trên một Dashboard được không?
Hoàn toàn được nhờ kiến trúc Pull-model. Bạn chỉ cần trỏ Prometheus về IP của các VPS đó. Lưu ý: Khi truyền metric qua Internet, bắt buộc phải dùng VPN (WireGuard) hoặc cấu hình Tường lửa (UFW) chặn port 9100 để không bị hacker soi cấu hình.
7. Node Exporter có giám sát được băng thông của các container Docker chạy trên VPS không?
Đo được nhưng không chính xác. Nhóm metric node_network_* sinh ra để đo card mạng vật lý (eth0). Việc đo các interface ảo (docker0, veth) rất nhiễu. Để soi băng thông chi tiết của từng container, hãy cài thêm công cụ cAdvisor.
Kết luận
Việc xây dựng hệ thống giám sát băng thông VPS chuyên sâu không chỉ giúp bạn chấm dứt chuỗi ngày đoán mò cấu hình mạng, mà còn là nền tảng để tối ưu hóa triệt để tài nguyên đang có. Hãy nhớ duy trì chính sách Data Retention (giữ log khoảng 30 ngày) để tránh tràn đĩa Monitoring Server, và sử dụng Recording Rules nếu cần tính toán rate() cho hàng trăm VPS cùng lúc.
Đừng đợi đến khi băng thông chạm đỉnh mới cuống cuồng nâng cấp. Hãy sử dụng dữ liệu từ Grafana để lên kế hoạch thay đổi kiến trúc, chẳng hạn như tiến hành cấu hình HAProxy Load Balancer phân tải cho cụm VPS Linux nhằm giảm tải cho các node đang bị nghẽn, hoặc tách các service tốn băng thông ra một cụm riêng.
Tuy nhiên, dù có tối ưu Kernel xuất sắc đến đâu, bạn cũng không thể vượt qua giới hạn vật lý của hạ tầng ảo hóa. Nếu biểu đồ Grafana liên tục báo động đỏ do sự chia sẻ tài nguyên quá đà từ máy chủ vật lý, bạn nên tham khảo bảng giá các gói VPS cấu hình khủng và cao nhất hiện nay để lên kế hoạch chuyển dịch sang các hệ thống có đường truyền Dedicated mạnh mẽ hơn.
Tài liệu tham khảo

Giải cứu ổ C Windows Server 2025: Cách dùng lệnh PowerShell dọn dẹp ổ đĩa tự động, an toàn

Giải pháp chống sập Server: Dùng script PowerShell giám sát VPS và bắn cảnh báo Telegram






