Cách xây dựng hệ thống Web Scraping chống block IP bằng Python, VPS và Rotating Proxy
2 giờ sáng, bạn tự tin gõ lệnh python main.py trên server production. Script đang hoạt động ổn định trên máy local trước đó bỗng nhiên ngừng hoạt động chỉ sau 5 phút. Màn hình console đỏ rực với hàng loạt mã lỗi HTTP 429 (Too Many Requests), hoặc tệ hơn là HTTP 403 (Forbidden). Trong một số trường hợp bị giới hạn ngầm, server vẫn trả về HTTP 200 OK, nhưng dữ liệu thu về toàn là rác hoặc một trang yêu cầu giải CAPTCHA.
Đối với các Data Engineer hay Developer làm dự án thu thập dữ liệu lớn, việc API bị rate-limit, IP bị block hay server mất kết nối giữa chừng là những vấn đề kỹ thuật diễn ra thường xuyên. Bạn không thể chỉ dùng vài thủ thuật time.sleep() chắp vá và hy vọng hệ thống vận hành trơn tru. Để giải quyết dứt điểm bài toán này, bạn cần tư duy ở cấp độ kiến trúc nhằm xây dựng một hệ thống Web Scraping phân tán, bền vững, vừa đảm bảo tốc độ thu thập vừa tuân thủ đạo đức và tôn trọng hạ tầng của target site.
Vậy làm thế nào để kết hợp sức mạnh của Python, độ tin cậy của hạ tầng VPS và sự linh hoạt của Rotating Proxy thành một pipeline hoàn chỉnh?
Để hiểu thêm về tính hợp pháp trong thu thập dữ liệu, bạn có thể tham khảo hướng dẫn chi tiết về cách xây dựng hệ thống thu thập dữ liệu thị trường với VPS và Proxy minh bạch, hợp pháp.
Nỗi đau của developer: Chạy script 5 phút là bị block IP & rate-limit
Nhiều developer khi mới bước chân vào mảng data extraction thường nghĩ đơn giản là chỉ cần đổi IP và giả lập HTTP Header User-Agent là xong. Tư duy này đã không còn phù hợp từ nhiều năm trước. Trong bối cảnh công nghệ hiện nay, các Web Application Firewall (WAF) và hệ thống Anti-bot (như Cloudflare, Akamai, DataDome) không chỉ đếm số lượng request mà còn soi xét traffic của bạn ở mức độ giao thức mã hóa.
Quản lý cấu hình TLS và bảo mật giao thức
Bạn đang dùng thư viện requests mặc định của Python để thu thập dữ liệu? Dù bạn có đổi sang IP dân cư chất lượng đến đâu, WAF vẫn nhận diện được bạn là một đoạn script tự động.
Trong quá trình kết nối với các hệ thống phân tán, việc cấu hình đúng giao thức mã hóa là rất quan trọng để đảm bảo tính toàn vẹn của dữ liệu. Các hệ thống hạ tầng mạng hiện đại luôn yêu cầu thiết lập kết nối an toàn với các tiêu chuẩn mã hóa nghiêm ngặt ở cấp độ giao thức. Giao thức HTTPS yêu cầu khởi tạo gói tin TLS Client Hello, trong đó định nghĩa rõ các bộ mã hóa (Ciphers) và phần mở rộng (Extensions) được hỗ trợ.
Việc tối ưu hóa cấu hình TLS không chỉ giúp tương thích tốt hơn với các chuẩn bảo mật khắt khe của máy chủ đích mà còn ngăn ngừa rủi ro kết nối bị từ chối. Thư viện requests sử dụng engine TLS mặc định của Python, nên thứ tự các ciphers và extensions hoàn toàn khác biệt so với một trình duyệt Google Chrome hay Safari thực tế. Nghiêm trọng hơn, nếu bạn thiết lập User-Agent là Chrome 122 nhưng cấu hình TLS lại là của Python, sự bất đồng bộ này chính là nguyên nhân dẫn đến việc bị chặn kết nối ngay lập tức. Hệ thống WAF sẽ đối chiếu các thông số này và ngắt kết nối của bạn ngay từ giai đoạn đầu trước cả khi dữ liệu HTTP được truyền đi.
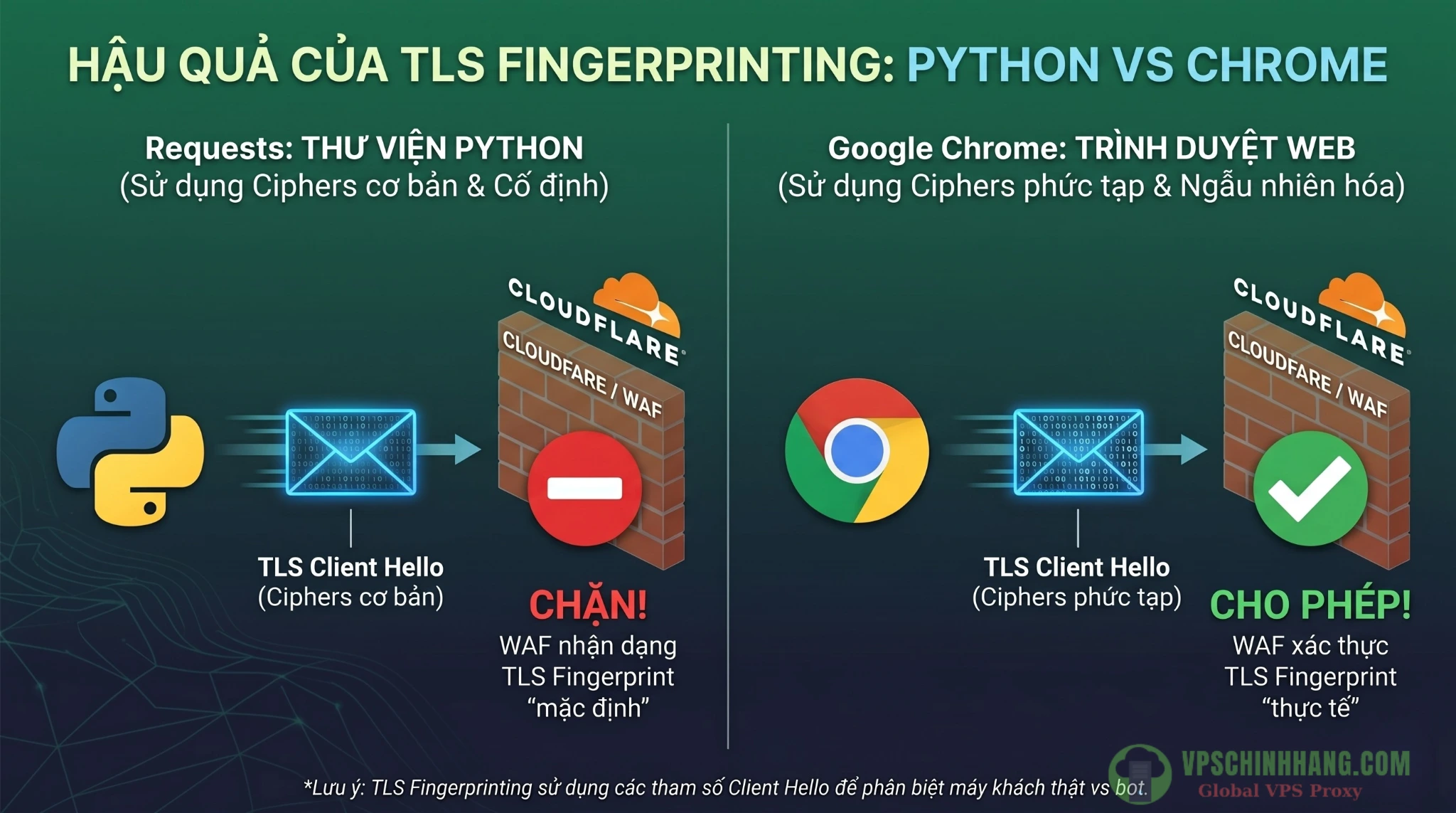
Việc cấu hình đúng các giao thức TLS Client Hello giúp đảm bảo tính tương thích và duy trì luồng kết nối an toàn với máy chủ đích thay vì bị chặn ngay lập tức.
Hiệu ứng Thundering Herd và nhịp độ máy móc
Khi đối mặt với lỗi 429 hoặc rớt mạng, phản xạ tự nhiên của nhiều dev là chèn time.sleep(5) vào vòng lặp except. Đây là một sai lầm nghiêm trọng tạo ra dấu hiệu kịch bản tự động cực kỳ rõ rệt.
- Nhịp độ máy móc (Mechanical Cadence): Con người không bao giờ lướt web với khoảng cách thời gian đều tăm tắp. Một script liên tục gửi request cách nhau đúng 5 giây tạo ra một mẫu traffic phi tự nhiên.
- Hiệu ứng Bầy đàn (Thundering Herd): Nếu bạn chạy hàng chục luồng (worker) song song và chúng cùng gặp lỗi, tất cả sẽ cùng tạm ngưng 5 giây. Ở giây thứ 6, chúng đồng loạt hoạt động trở lại và gửi lượng lớn request đến server cùng một lúc. Tình trạng này tạo ra các đỉnh tăng vọt (spikes) cục bộ đan xen với các khoảng ngưng trệ, khiến server đối phương bị quá tải nhưng hiệu suất thu thập dữ liệu của bạn lại cực thấp.
Kiến trúc chuẩn cho hệ thống Web Scraping phân tán & bền vững
Khi thu thập dữ liệu quy mô lớn, việc sử dụng một script Python đơn lẻ chạy trên một máy tính sẽ nhanh chóng dẫn đến việc kẹt CPU/RAM (đặc biệt khi chạy headless browser tiêu tốn ~500MB RAM/tab), và toàn bộ quá trình sẽ sụp đổ nếu script gặp lỗi. Bạn cần một kiến trúc phân tán.
Tầng hạ tầng: Multi-VPS, Docker và Celery
Đừng dồn toàn bộ workload vào một máy chủ. Hạ tầng chuẩn đòi hỏi sự chia nhỏ công việc một cách thông minh:
- Docker (Đóng gói môi trường): Triển khai Python cục bộ rất dễ sinh lỗi dependency. Docker giúp bạn đóng gói mã nguồn và thư viện vào một container cô lập. Một container chuyên chạy Scrapy spider, một container chuyên chạy Database (PostgreSQL). Triển khai hệ thống lên máy chủ mới chỉ tốn một dòng lệnh. Bạn có thể tham khảo thêm về hướng dẫn cài đặt Docker trên VPS Ubuntu dành cho người mới bắt đầu để nắm rõ quy trình.
- Multi-VPS (Phân tán tài nguyên): Sử dụng nhiều máy chủ ảo (VPS) ở các vùng địa lý khác nhau giúp nhân rộng sức mạnh xử lý và vượt qua giới hạn phần cứng của một máy đơn lẻ.
- Celery (Bộ não điều phối): Vượt trội hơn hẳn
crontabtruyền thống, Celery là một Distributed Task Queue. Nó đẩy các URL cần thu thập vào Redis (Message Broker) và phân phát cho các worker nằm rải rác trên các VPS. Celery quản lý hoàn hảo việc tự động thử lại khi lỗi (retry), giới hạn thời gian (timeout) và định tuyến tác vụ.
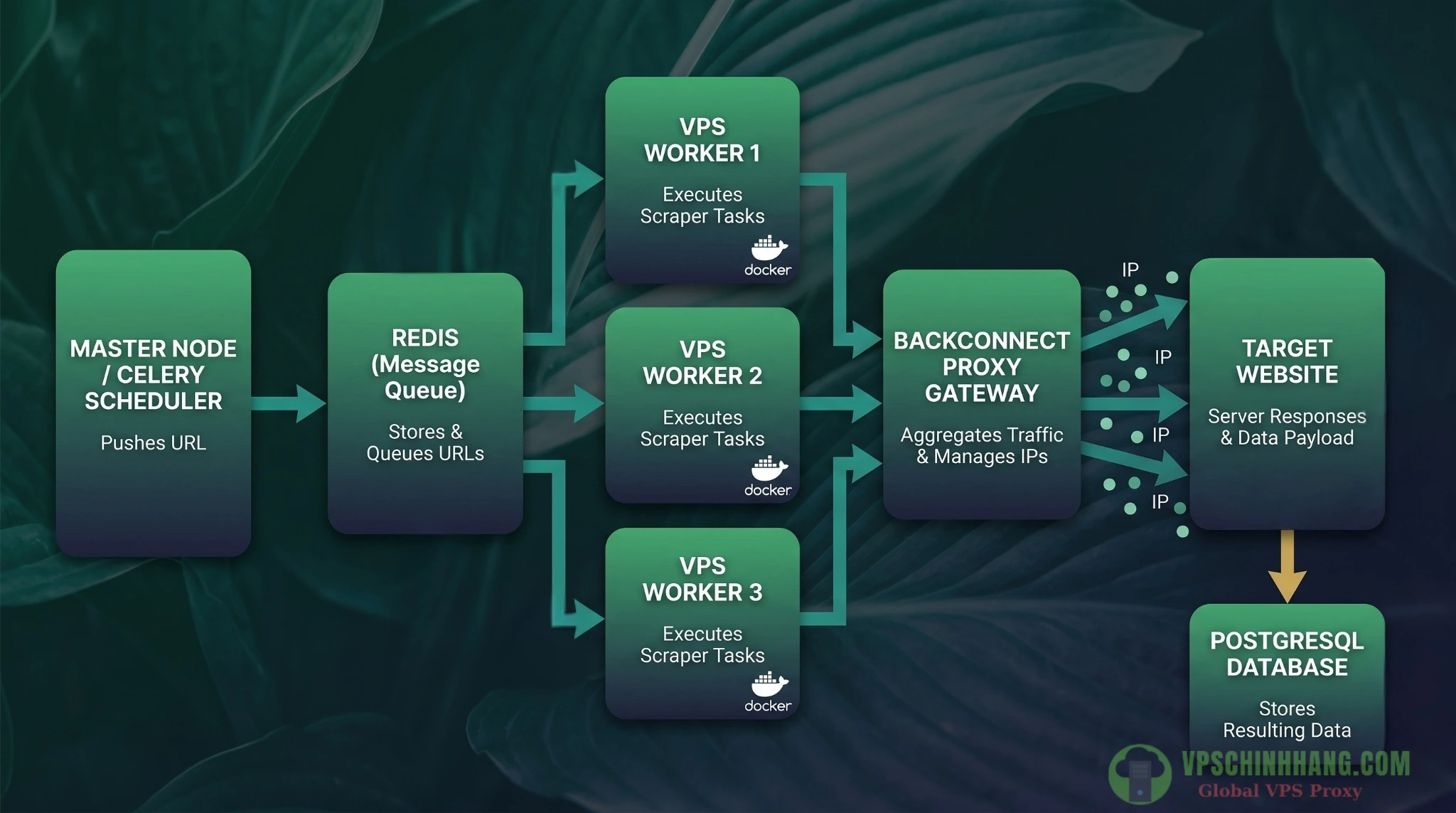
Kiến trúc Web Scraping phân tán giúp hệ thống chịu tải cao, dễ dàng mở rộng (scale) và không bị sụp đổ toàn hệ thống khi một node gặp lỗi.
Tầng mạng: Tối ưu hóa Rotating Proxy
Thay vì thu thập proxy miễn phí (vừa tốc độ thấp vừa kém an toàn) và tự luân phiên, các hệ thống chuyên nghiệp sử dụng Backconnect Proxy (Proxy xoay API). Bạn chỉ kết nối vào một máy chủ cổng duy nhất (Gateway), và nhà cung cấp sẽ tự định tuyến request của bạn qua một kho hàng triệu IP dân cư. Hoặc nếu dự án yêu cầu độ bảo mật cao, bạn có thể tham khảo cách tự build Proxy Socks5 private trên VPS nhằm thiết lập giải pháp bảo mật dữ liệu cho developer.
Có 2 chiến lược cốt lõi:
- Per-Request (Random IP): Xoay IP mới cho mỗi một HTTP request riêng biệt. BẮT BUỘC dùng cho các tác vụ không lưu trạng thái (stateless) như thu thập giá sản phẩm, kiểm tra quảng cáo, theo dõi thứ hạng tìm kiếm (SERP). Nó tối đa hóa sự phân tán mạng.
- Session Sticky (Giữ IP theo phiên): Cố định một IP trong khoảng 5 đến 30 phút. BẮT BUỘC dùng khi bạn cần duy trì phiên làm việc, giữ cookie giỏ hàng hoặc điền form đa bước. Nếu bạn đổi IP giữa một quy trình xác thực, hệ thống kiểm soát của target site sẽ lập tức ngắt kết nối hoặc hủy giao dịch.
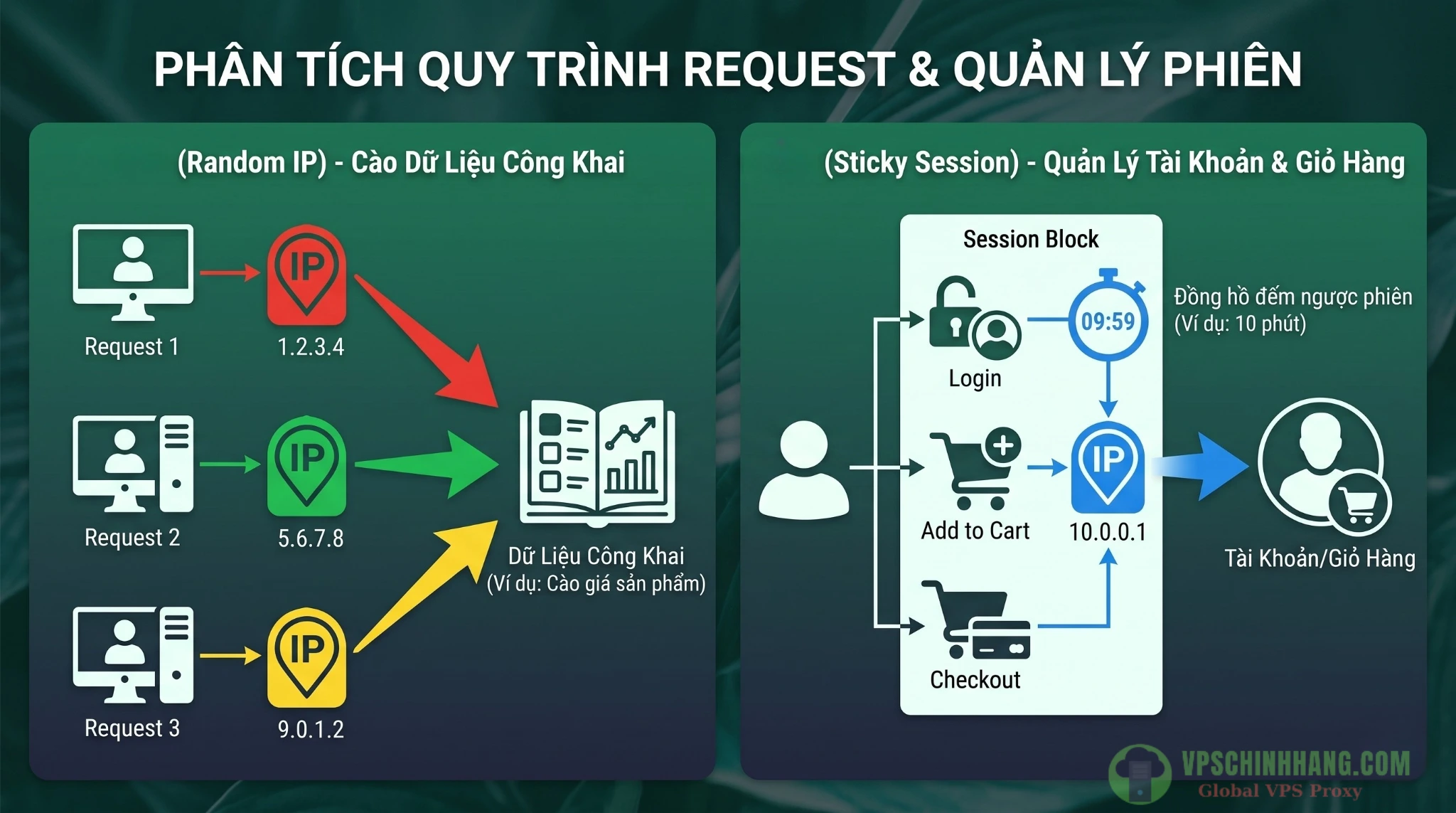
Việc lựa chọn đúng chiến lược xoay IP (Per-request hay Sticky Session) quyết định tính liên tục của tác vụ thu thập dữ liệu.
Tầng giám sát: Đừng chạy code không kiểm soát
Hãy setup Prometheus và Grafana để theo dõi hệ thống Web Scraping của bạn. Giám sát tỷ lệ lỗi (Error Rate) và thời gian phản hồi (Latency). Nếu tỷ lệ lỗi 403 tăng vọt lên 20%, Grafana sẽ alert ngay vào Telegram để bạn kiểm tra xem target site vừa update rule bảo vệ hay proxy đang bị quá tải băng thông.
Để nắm rõ quy trình thiết lập, bạn có thể xem hướng dẫn chi tiết về cách xây dựng Dashboard giám sát VPS Linux với Prometheus và Grafana.
Luồng kỹ thuật tích hợp Python: Từ async đến vượt fingerprinting
Khi phần cứng và mạng đã hoàn thiện, logic code của bạn phải đủ tinh tế để hoạt động ổn định trên môi trường mạng phức tạp.
Tối ưu hóa kết nối mạng với curl_cffi
Trong một số trường hợp hạ tầng yêu cầu cấu hình mạng khắt khe, thư viện requests có thể không hỗ trợ đầy đủ các giao thức mới nhất. Khi đó, việc chuyển sang sử dụng curl_cffi là một giải pháp tối ưu.
Thư viện này cung cấp khả năng tinh chỉnh sâu vào lớp giao thức TLS và HTTP/2, thậm chí hỗ trợ cả HTTP/3. Nhờ vậy, hệ thống thu thập dữ liệu của bạn có thể thiết lập các luồng giao tiếp bảo mật, tối ưu hóa hiệu suất truyền tải tín hiệu và duy trì kết nối xuyên suốt với các máy chủ đích yêu cầu chuẩn mã hóa cao mà không cần phải viết lại quá nhiều code vì API của nó tương đồng với requests.
Xử lý mã lỗi 429 với Exponential Backoff & Jitter
Để dập tắt hiệu ứng Thundering Herd, bạn không được dùng thời gian chờ cố định. Hãy áp dụng thuật toán Exponential Backoff and Jitter, một tiêu chuẩn được chính kiến trúc sư của AWS khuyên dùng.
- Exponential Backoff: Nhân đôi thời gian chờ sau mỗi lần thất bại (2s, 4s, 8s…).
- Jitter (Độ trễ ngẫu nhiên): Yếu tố then chốt. Thay vì chờ đúng 8 giây, hệ thống sẽ thêm hoặc bớt một lượng thời gian ngẫu nhiên (Full Jitter, Equal Jitter, hoặc Decorrelated Jitter).
Jitter giúp làm phẳng traffic, phá vỡ các cụm đụng độ, giảm thiểu sự cạnh tranh giữa các worker trên cùng một phần nghìn giây. Nó giúp giảm tải cho cả server đích lẫn hệ thống thu thập dữ liệu của bạn, đồng thời hoàn thành batch công việc nhanh hơn rất nhiều so với backoff thông thường.
Áp dụng Circuit Breaker (cầu dao tự động) tránh DDoS
Khi target site đang quá tải và liên tục trả về mã lỗi HTTP 500 hoặc 503, việc script của bạn liên tục dùng proxy xoay để retry không khác gì một cuộc tấn công DDoS.
Để hiểu máy chủ đối phương đang phải gồng gánh và chống đỡ ra sao, bạn có thể tham khảo bài viết về cách giới hạn Rate Limit trên Nginx nhằm chặn đứng tấn công DDoS Layer 7 cho VPS.
Hãy triển khai Design Pattern Circuit Breaker (Cầu dao tự động) mô phỏng cỗ máy trạng thái với 3 nấc:
- Closed (Đóng): Hoạt động bình thường. Nếu số lượng lỗi 5xx vượt ngưỡng, cầu dao sẽ ngắt kết nối.
- Open (Mở): Trong một khoảng thời gian chờ (ví dụ 10 phút), mọi request từ scraper vào target site bị từ chối ngay ở cấp độ local, không tốn băng thông mạng, không ngốn RAM/CPU của VPS để chờ đợi. Điều này bảo vệ tài nguyên của hệ thống bạn khỏi lỗi dây chuyền (cascading failures) và chừa không gian xử lý cho server đối phương.
- Half-Open (Mở một nửa): Gửi vài request thăm dò. Nếu thành công (máy chủ đã phục hồi), cầu dao Đóng lại. Nếu thất bại, cầu dao Mở ra tiếp.
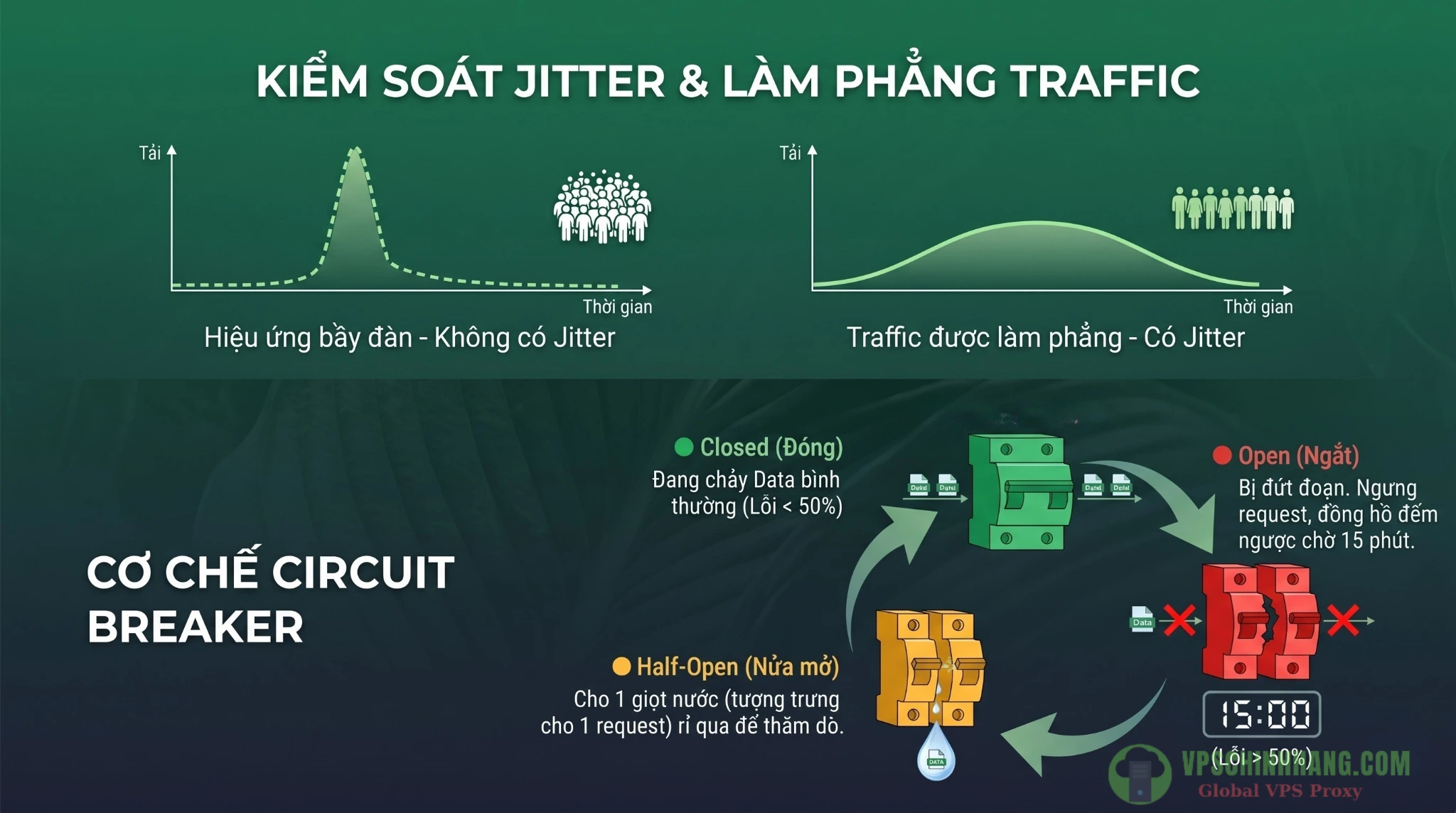
Jitter giúp làm phẳng lưu lượng (tránh hiệu ứng bầy đàn Thundering Herd), trong khi Circuit Breaker bảo vệ máy chủ đích khi xảy ra lỗi 5xx.
Best practices thu thập dữ liệu an toàn, hợp pháp & tôn trọng target site
Xây dựng hệ thống scraping mạnh mẽ không có nghĩa là bạn được quyền gây áp lực lên hạ tầng của người khác. Đạo đức dữ liệu (Data Ethics) là yếu tố phân định giữa một kỹ sư chân chính và những hành vi thiếu chuyên nghiệp.
Sự thật về robots.txt, crawl-delay và Googlebot
Theo tiêu chuẩn RFC 9309, tệp robots.txt không phải là một cơ chế ủy quyền truy cập hay bảo mật. Nó là một bộ quy ước để bạn kiểm tra xem đường dẫn nào được Allow hoặc Disallow. Tôn trọng các chỉ thị này là minh chứng đầu tiên cho thiện chí của crawler.
Tuy nhiên, đừng tin vào Crawl-delay. Đây là một chỉ thị không chính thức (unofficial) và được các hệ thống diễn giải rất mâu thuẫn (Bing coi là cửa sổ thời gian, Yandex coi là thời gian chờ tối thiểu). Đặc biệt, Googlebot bỏ qua hoàn toàn chỉ thị này. Thay vào đó, nó tự động đo lường độ trễ của máy chủ (latency) để tự điều chỉnh tốc độ. Nếu server phản hồi chậm, Googlebot tự giảm tải; nếu server khỏe, nó tăng tốc. Hệ thống Web Scraping của bạn cũng nên xây dựng một cơ chế tự thích ứng thông minh như vậy thay vì cấu hình cứng một con số tĩnh.
Tuân thủ header Retry-After
Khi bạn gặp mã lỗi HTTP 429 (Too Many Requests) hoặc 503, hãy ngay lập tức kiểm tra HTTP Header trả về. Theo tiêu chuẩn RFC 6585, máy chủ thường đính kèm header Retry-After (chứa số giây hoặc mốc thời gian cụ thể).
Việc tuân thủ header này quan trọng hơn bất kỳ thuật toán tự đoán thời gian chờ nào. Nó cung cấp cho cầu dao tự động của bạn một thời gian biểu chính xác để tạm ngưng, ngăn chặn việc làm kiệt quệ tài nguyên luồng (threads) của VPS do cố gắng kết nối lại quá sớm, đồng thời giúp máy chủ đích không bị bóp nghẹt thêm.
Bài học pháp lý từ vụ kiện hiQ Labs v. LinkedIn
Làm sao để chắc chắn bạn không dính vào rắc rối pháp lý? Hãy nhìn vào phán quyết cốt lõi của Tòa phúc thẩm Vòng 9 Hoa Kỳ trong vụ kiện hiQ Labs v. LinkedIn.
Tòa án phán quyết rằng Đạo luật Lạm dụng và Lừa đảo Máy tính (CFAA) không áp dụng đối với dữ liệu có sẵn công khai trên internet. Việc bạn thu thập thông tin từ các trang mở (không bị che bởi mật khẩu hay yêu cầu xác thực) không cấu thành tội truy cập trái phép.
Tuy nhiên, đừng chủ quan. Nếu bạn cố tình can thiệp hệ thống, hoặc tạo ra quá nhiều request làm sập mạng (DDoS), bạn vẫn sẽ bị truy tố. Ngoài ra, việc vượt qua các cổng xác thực có thể khiến bạn vi phạm hợp đồng dân sự liên quan đến Thỏa thuận người dùng (User Agreement). Nguyên tắc vàng là: Chỉ thu thập Public Data và giới hạn tốc độ một cách hợp lý.
Câu hỏi thường gặp (FAQ)
1. Tại sao dùng Python requests lại liên tục bị lỗi 403 Forbidden?
Nguyên nhân thường xuất phát từ việc cấu hình gói tin TLS không đồng bộ. Thư viện requests có cấu trúc gói tin mặc định không tương thích với các tiêu chuẩn bảo mật khắt khe của hệ thống WAF hiện đại, dẫn đến việc bị từ chối kết nối (403).
Giải pháp: Đổi sang dùng thư viện curl_cffi để tối ưu hóa cấu hình mã hóa và tương thích tốt hơn với chuẩn giao thức mạng.
2. Làm sao để xử lý lỗi khi thu thập dữ liệu qua các hệ thống WAF?
Hệ thống WAF thường kiểm tra cấu hình mạng ở lớp giao thức và yêu cầu thực thi JavaScript.
Giải pháp: Tối ưu cấu hình giao thức bằng curl_cffi kết hợp Proxy. Đối với các trang yêu cầu JavaScript, bạn cần triển khai trình duyệt Headless (như Playwright) để xử lý logic render của trang web một cách đầy đủ.
3. Tại sao tôi đã dùng Proxy xoay vòng nhưng hệ thống vẫn bị block IP?
Proxy chỉ giúp bạn phân tán luồng truy cập, không quyết định được tần suất tải. Nếu bạn gửi request liên tục với khoảng cách thời gian cố định (thiếu Jitter) hoặc cố tình gửi lượng lớn request dù server đang báo tải nặng (429), hệ thống bảo mật sẽ chặn hoàn toàn dải IP proxy đó.
4. Khi nào nên dùng Residential Proxy thay vì Datacenter Proxy?
- Datacenter Proxy: Chi phí thấp, tốc độ cao nhưng dễ bị chặn do dải IP thuộc các trung tâm dữ liệu. Phù hợp để thu thập dữ liệu trên các hệ thống không có giới hạn truy cập khắt khe.
- Residential Proxy (Dân cư): Tốc độ ổn định và độ tin cậy cao. Khuyên dùng khi làm việc với các nền tảng có hệ thống quản lý lưu lượng mạng phức tạp.
5. Làm thế nào để xử lý hệ thống chặn tự động một cách hiệu quả nhất?
Sử dụng thuật toán Exponential Backoff kèm Jitter để làm phẳng traffic, tránh kích hoạt các trigger bảo vệ. Nếu tỷ lệ từ chối kết nối tăng vọt, hãy kích hoạt ngay Circuit Breaker (Ngắt cầu dao) để ngưng request thay vì liên tục cố gắng truy cập lại.
6. Nên chọn cấu hình VPS như thế nào để chạy Worker thu thập dữ liệu?
Không nên dồn tài nguyên vào một máy chủ quá lớn. Hãy ưu tiên Scale ngang (Horizontal Scaling). Tối ưu nhất là triển khai cụm 3-5 VPS Linux cấu hình vừa phải (2-4 vCPU, 4-8GB RAM), sau đó cài đặt Docker để đóng gói môi trường và dùng Celery phân bổ tác vụ.
7. Việc xây dựng hệ thống Web Scraping có vi phạm pháp luật không?
Không, nếu bạn chỉ thu thập Dữ liệu công khai (Public Data) theo án lệ hiQ Labs v. LinkedIn. Có, nếu bạn cố tình can thiệp vào các khu vực bảo mật không được cấp phép, hoặc gửi request với tốc độ quá lớn gây từ chối dịch vụ cho máy chủ đích (DDoS).
Kết luận
Sở hữu một hệ thống Web Scraping hoạt động ổn định, dễ dàng scale và hạn chế tối đa rủi ro gián đoạn dịch vụ là sự tổng hòa của tư duy kiến trúc toàn diện. Bạn cần sự ổn định của hệ thống phân tán Multi-VPS / Docker / Celery, khả năng phân bổ kết nối mạng của Backconnect Proxy, và sự tinh tế trong code Python (curl_cffi, Jitter, Circuit Breaker).
Tối ưu hóa khả năng tương thích với hạ tầng đích là một thành tựu kỹ thuật đáng nể, nhưng việc kiểm soát luồng giao tiếp sao cho không gây quá tải đến máy chủ đối phương mới là đẳng cấp cao nhất của một Data Engineer. Hãy triển khai các cơ chế kiểm soát rate-limit ngay hôm nay, tuân thủ nghiêm ngặt việc chỉ thu thập dữ liệu công khai, và biến pipeline của bạn trở thành một hệ thống bền vững, hợp pháp và đầy trách nhiệm.
Tài liệu tham khảo